Bo Wu*, Sid Wang*, Yunhao Tang*, Jia Ding*, et al.
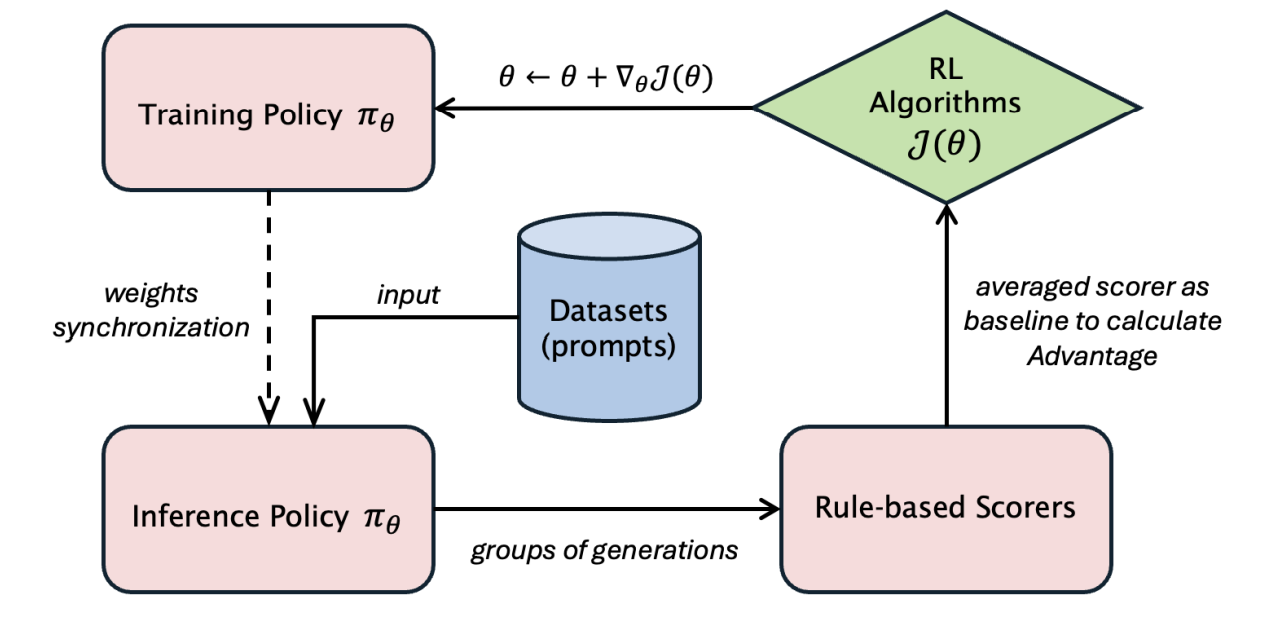
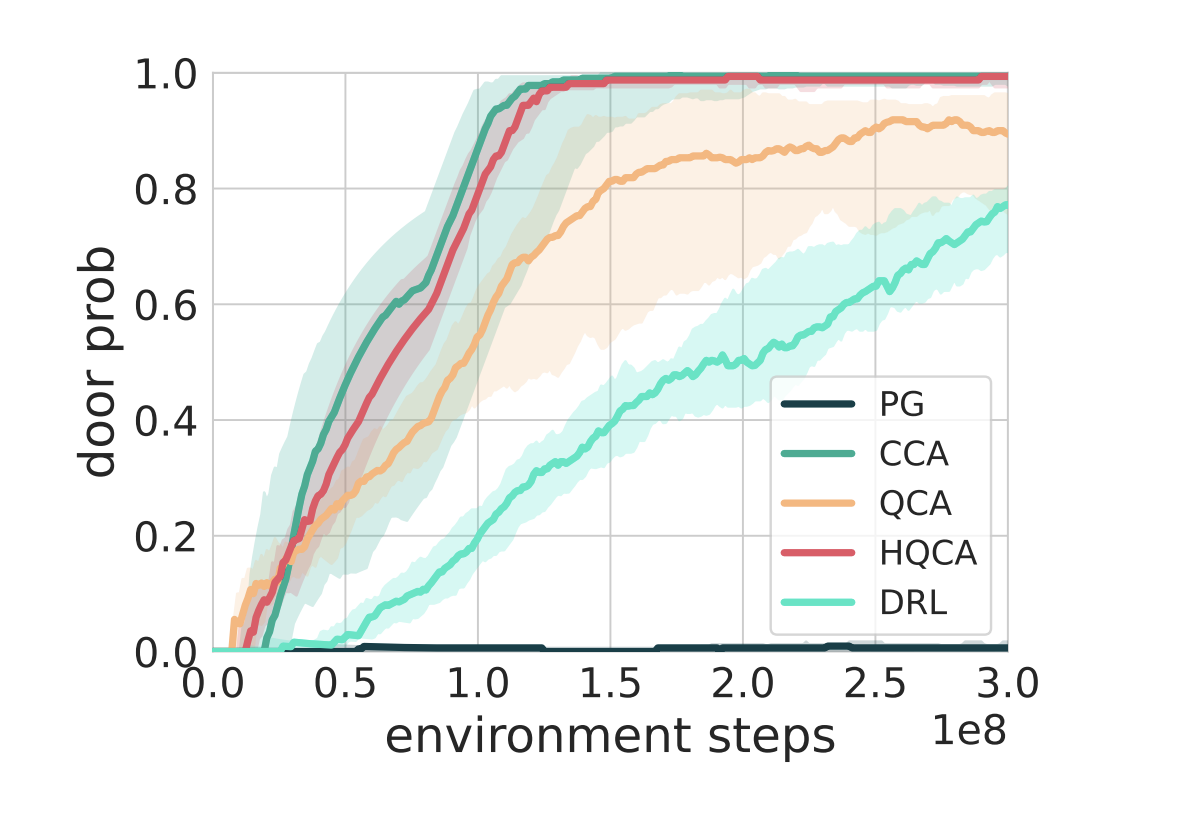
LlamaRL is the first distributed asynchronous off-policy RL stack that powers large-scale Llama training internal to Llama research.
My past research work focused on the understanding and developments of deep reinforcement learning algorithms and systems, spanning the following non-exhaustive list of topics:
See Google Scholar for the full list.
Bo Wu*, Sid Wang*, Yunhao Tang*, Jia Ding*, et al.
LlamaRL is the first distributed asynchronous off-policy RL stack that powers large-scale Llama training internal to Llama research.
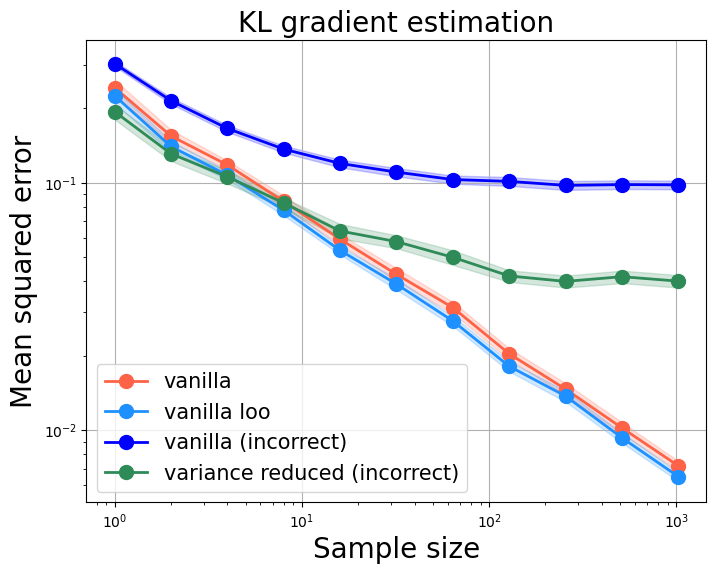
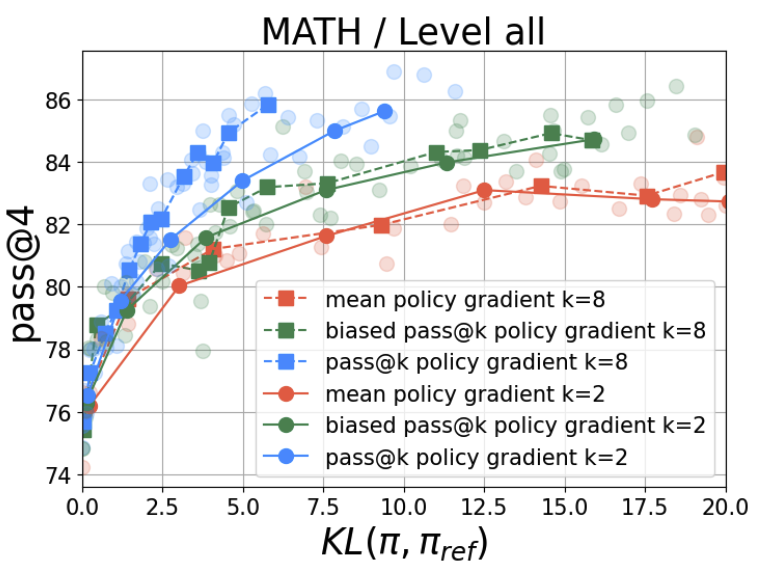
On a few pitfalls in KL divergence gradient estimation for RL
Yunhao Tang, Rémi Munos.
We highlight two pitfalls on building KL gradient estimate for RL applications, as well as their practical impact.
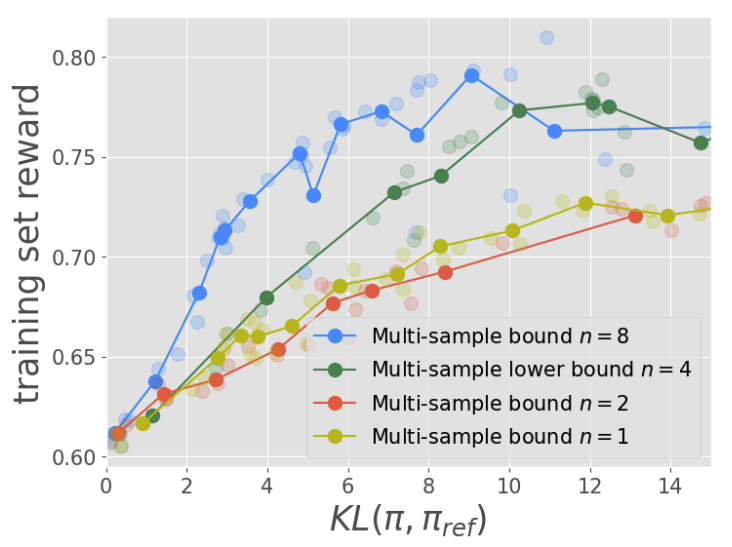
Beyond Verifiable Rewards: Scaling Reinforcement Learning for Language Models to Unverifiable Data
Yunhao Tang, Sid Wang, Lovish Madaan, Rémi Munos.
Arxiv, NeurIPS 2025
We extend RL training beyond verifiable reward with Jensen's Evidence lower bound Policy Optimization (JEPO).
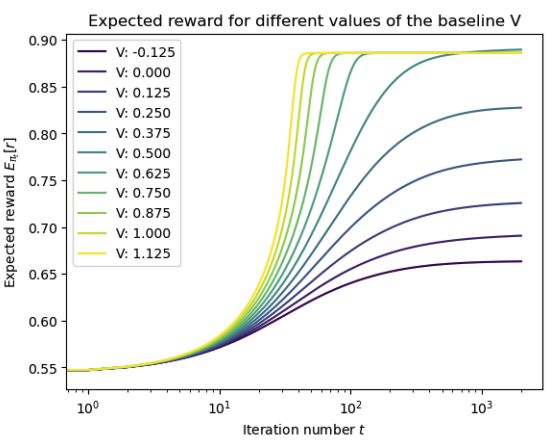
Asymmetric REINFORCE for off-policy reinforcement learning: balancing positive and negative rewards
Charles Arnal, Gaëtan Narozniak, Vivien Cabannes, Yunhao Tang, Julia Kempe, Rémi Munos.
Arxiv, NeurIPS 2025
We analyze an asymmetric version of REINFORCE algorithm, which naturally appears in the off-policy case.
Optimizing Language Models for Inference Time Objectives using Reinforcement Learning
Yunhao Tang*, Kunhao Zheng*, Gabriel Synnaeve, Rémi Munos*.
Arxiv, ICML 2025
Simple inference aware finetuning algorithms can greatly improve test time performance.
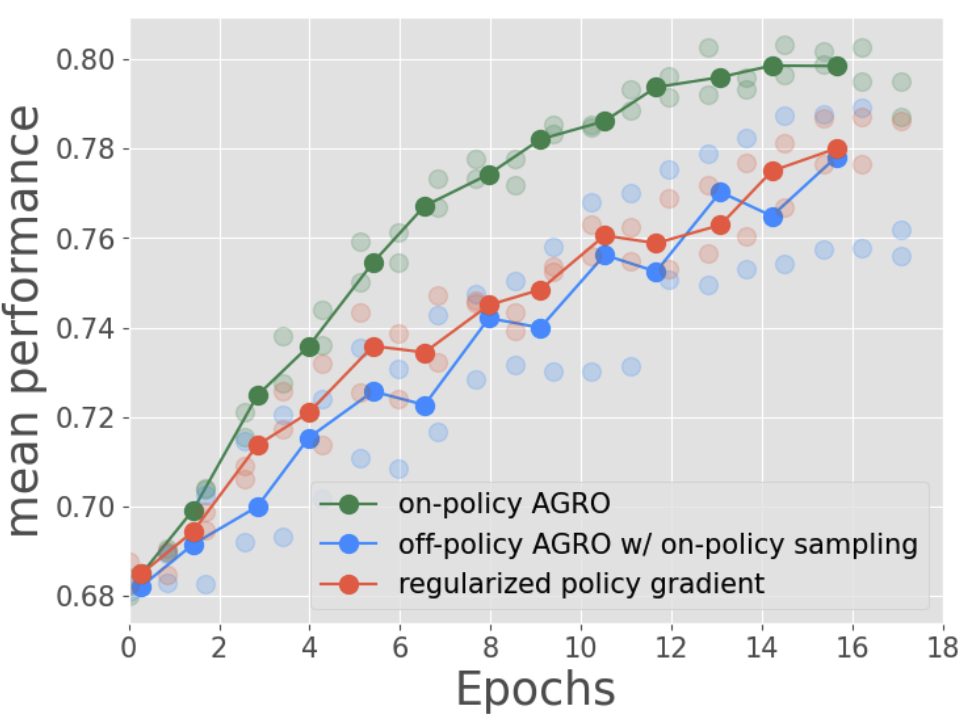
RL-finetuning LLMs from on- and off-policy data with a single algorithm
Yunhao Tang*, Taco Cohen, David W. Zhang, Michal Valko, Rémi Munos*.
Arxiv, AISTATS 2026
We propose Any Generation Reward Optimization (AGRO), a fine-tuning algorithm that leverages data from arbitrary sources for model alignment.
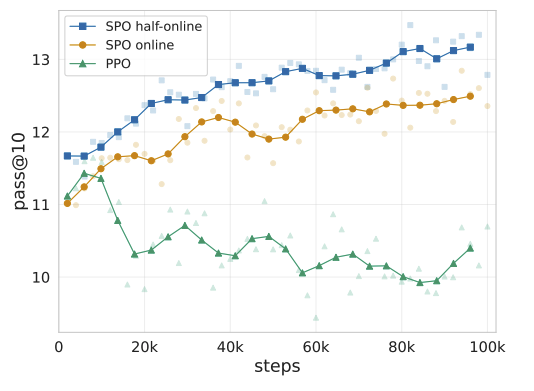
Soft Policy Optimization: Online Off-Policy RL for Sequence Models
Taco Cohen*, David W. Zhang*, Kunhao Zheng, Yunhao Tang, Rémi Munos, Gabriel Synnaeve.
Soft policy optimization outperforms PPO on code generation tasks.
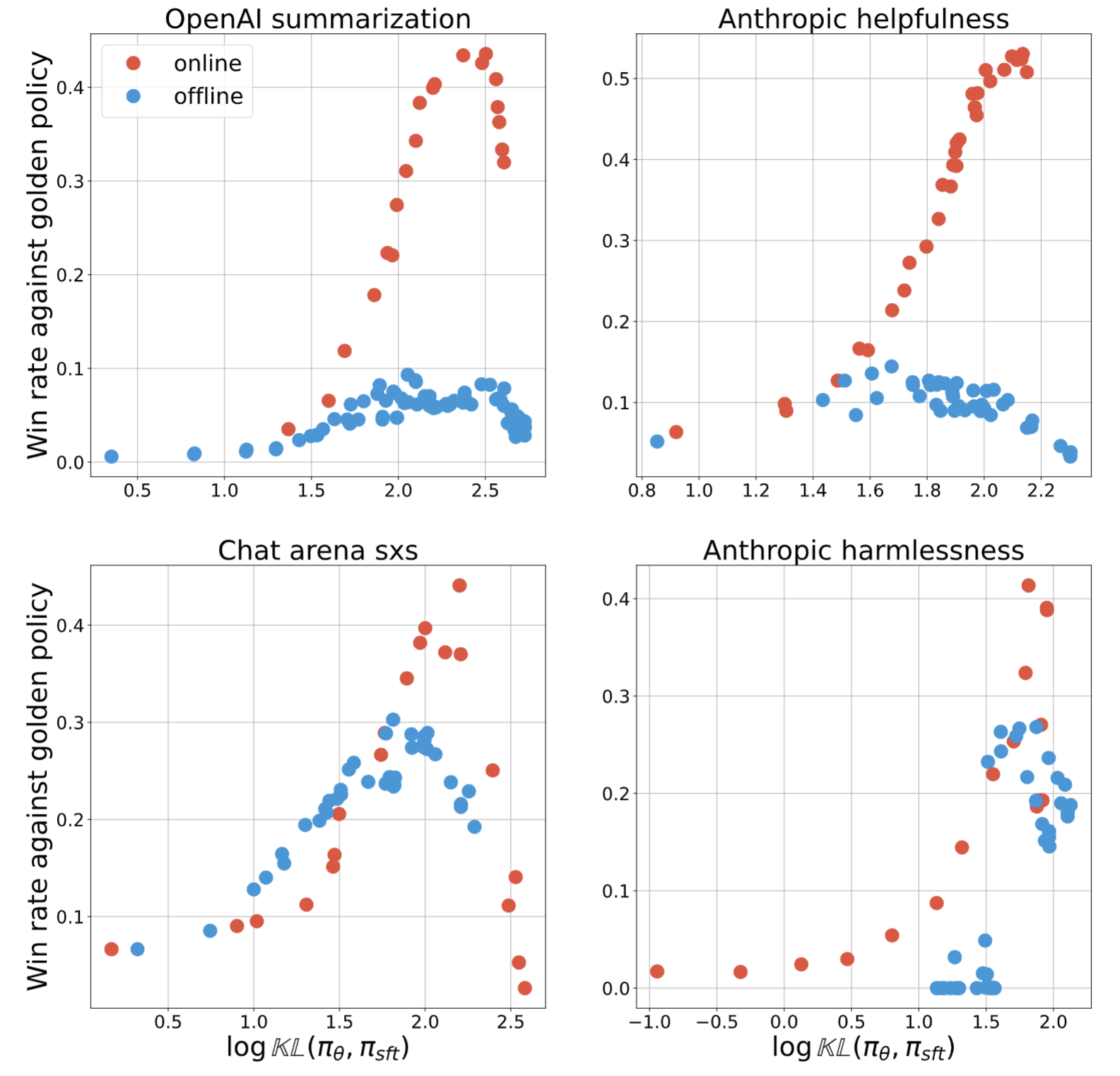
Understanding the Performance Gap between Online and Offline Alignment Algorithms
Yunhao Tang, Daniel Guo, Zeyu Zheng, Daniele Calandriello, Yuan Cao, Eugene Tarassov, Rémi Munos, Bernardo Avila Pires, Michal Valko, Yong Cheng, Will Dabney.
Is online RL really necessary for AI alignment, or do offline algorithms suffice?
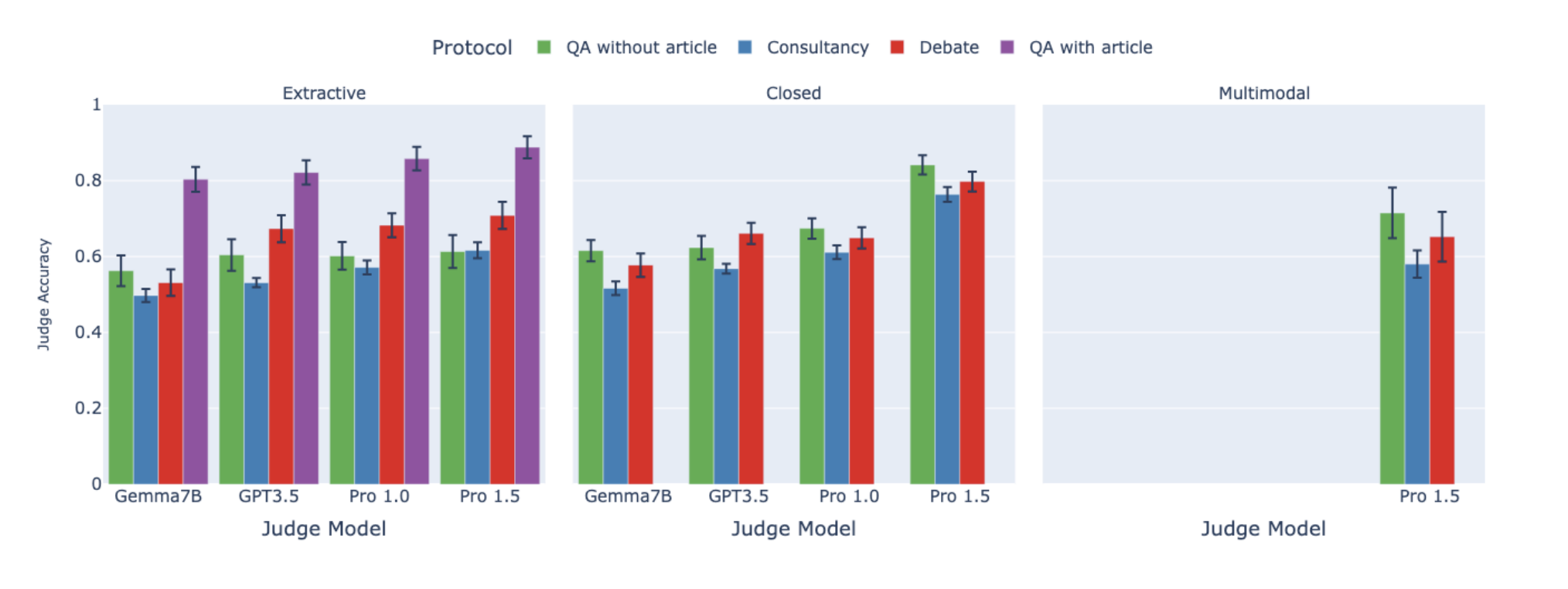
On scalable oversight with weak LLMs judging strong LLMs
Zachary Kenton*, Noah Y. Siegel*, Janos Kramar, Jonah Brown-Cohen, Samuel Albanie, Jannis Bulian, Rishabh Agarwal, David Lindner, Yunhao Tang, Noah D. Goodman, Rohin Shah.
Arxiv, NeurIPS 2024
We benchmark important existing scalable-oversight protocols in a comprehensive suite of QA tasks.
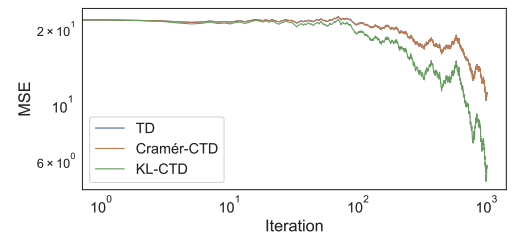
Tyler Kastner, Mark Rowland, Yunhao Tang, Murat A. Erdogdu, Amir M. Farahmand.
We seek to close another important theory-practice gap in distributional RL.
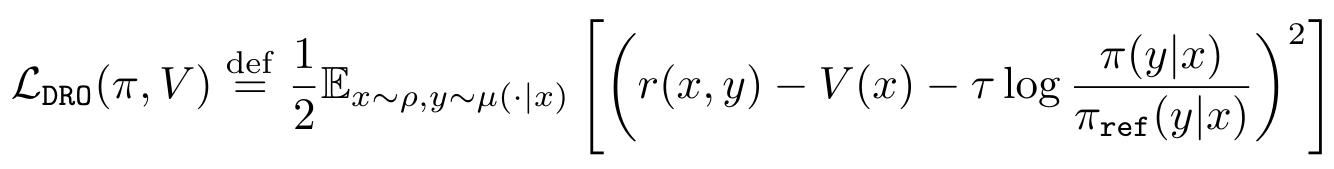
Offline Regularised Reinforcement Learning for Large Language Models Alignment
Pierre Harvey Richemond, Yunhao Tang, Daniel Guo, Daniele Calandriello, Mohammad Gheshlaghi Azar, Rafael Rafailov, Bernardo Avila Pires, Eugene Tarassov, Lucas Spangher, Will Ellsworth, Aliaksei Severyn, Jonathan Mallinson, Lior Shani, Gil Shamir, Rishabh Joshi, Tianqi Liu, Rémi Munos, Bilal Piot.
When human feedback is pointwise rather than pairwise, we propose direct reward optimization (DRO).
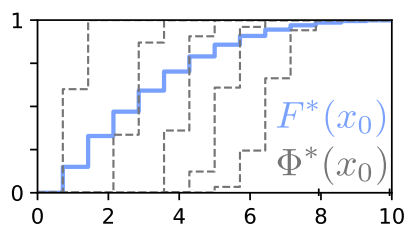
Near-Minimax-Optimal Distributional Reinforcement Learning with a Generative Model
Mark Rowland, Li Kevin Wenliang, Rémi Munos, Clare Lyle, Yunhao Tang, Will Dabney.
NeurIPS 2024
We show a minimax optimal model based algorithm for distributional RL.
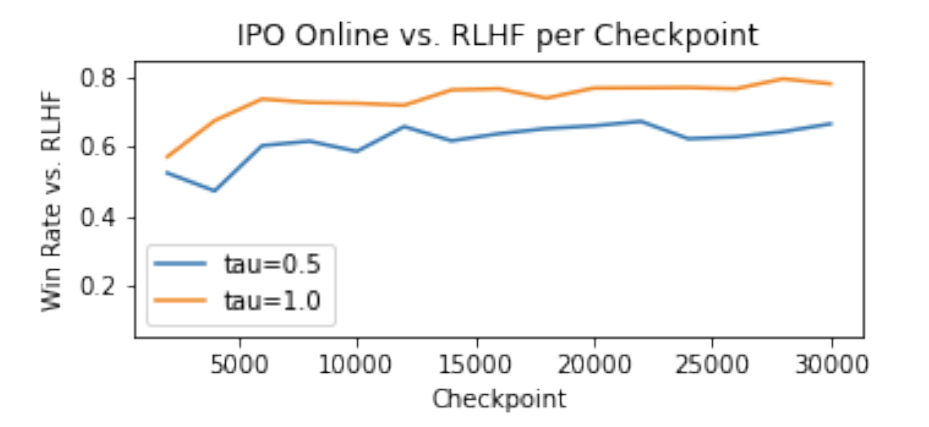
Human Alignment of Large Language Models Through Online Preference Optimization
Daniele Calandriello, Daniel Guo, Rémi Munos, Mark Rowland, Yunhao Tang, Bernardo Avila Pires, Pierre Harvey Richemond, Charline Le Lan, Michal Valko, Tianqi Liu, Rishabh Joshi, Zeyu Zheng, Bilal Piot.
Arxiv, ICML 2024
Online preference optimization as an alignment technique is intimately related to Nash equilibrium.
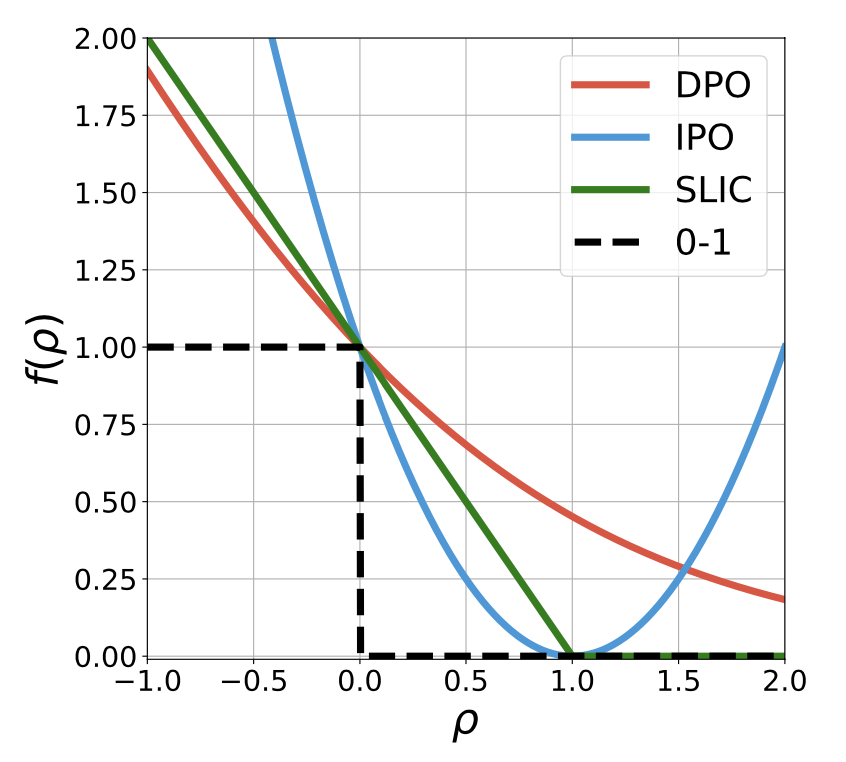
Generalized Preference Optimization: A Unified Approach to Offline Alignment
Yunhao Tang, Daniel Zhaohan Guo, Zeyu Zheng, Daniele Calandriello, Rémi Munos, Mark Rowland, Pierre Harvey Richmond, Michal Valko, Bernardo Avila Pires, Bilal Piot.
Arxiv, ICML 2024
GPO unifies alignment algorithms such as DPO, IPO and SLiC as special cases.
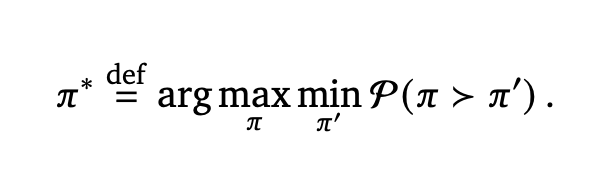
Nash Learning from Human Feedback
Rémi Munos*, Michal Valko*, Daniele Calandriello*, Mohammad Gheshlaghi Azar*, Mark Rowland*, Daniel Guo*, Yunhao Tang*, Matthieu Geist*, Thomas Mesnard, Andrea Michi, Marco Selvi, Sertan Girgin, Nikola Momchev, Olivier Bachem, Daniel J. Mankowitz, Doina Precup, Bilal Piot*.
Arxiv, ICML 2024
In aligning large language models, we search for Nash Equilibrium naturally defined via pairwise human feedback.
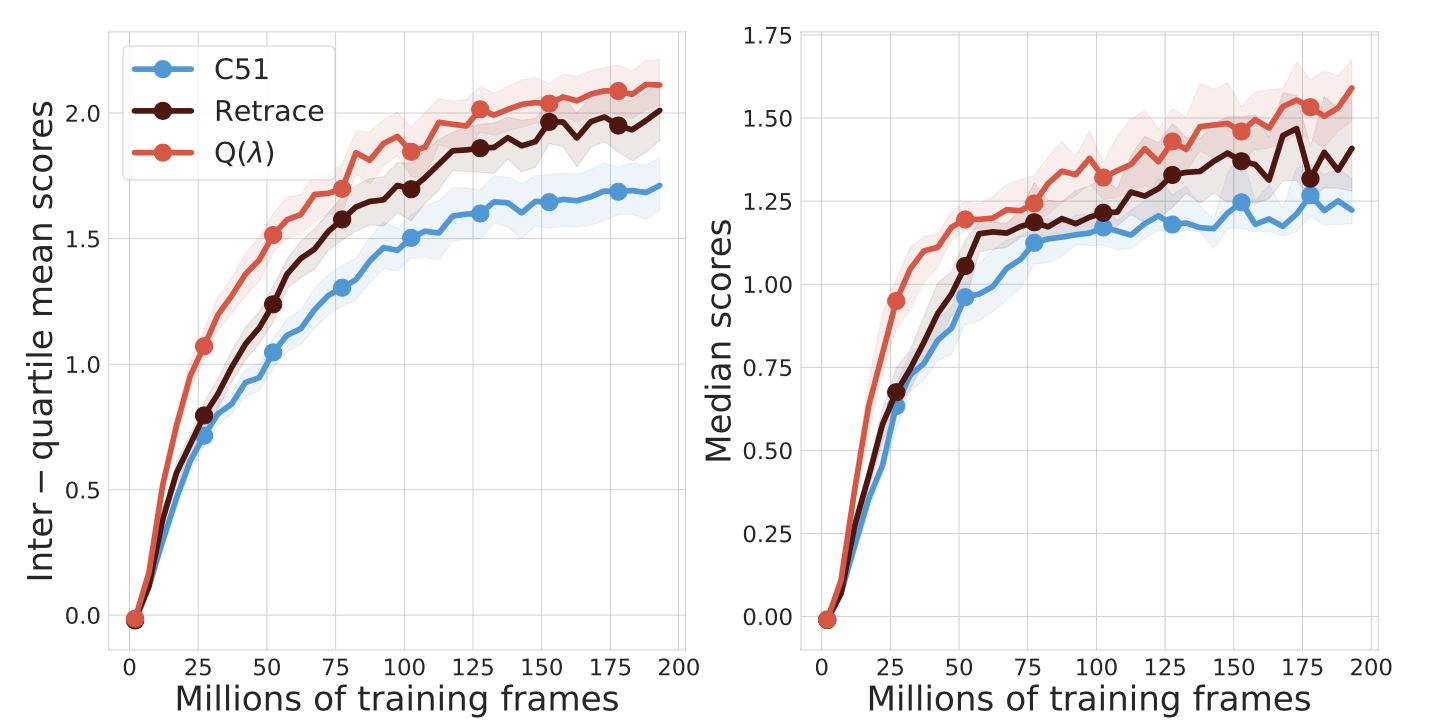
Off-policy Distributional Q(λ): Distributional RL without Importance Sampling
Yunhao Tang, Mark Rowland, Rémi Munos, Bernardo Avila Pires, Will Dabney.
Arxiv, AISTATS 2026
Another addition to the family of off-policy distributional RL algorithms, without the need for importance sampling.
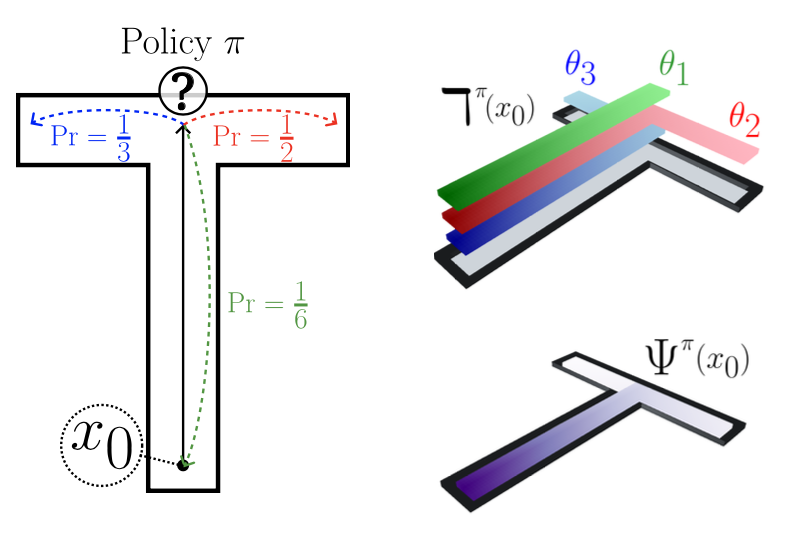
A Distributional Analogue to the Successor Representation
Harley Wiltzer*, Jesse Farebrother*, Arthur Greton, Yunhao Tang, André Barreto, Will Dabney, Marc G. Bellemare, Mark Rowland.
Arxiv, ICML 2024
We shed light on what distributional equivalence of successor representations look like.
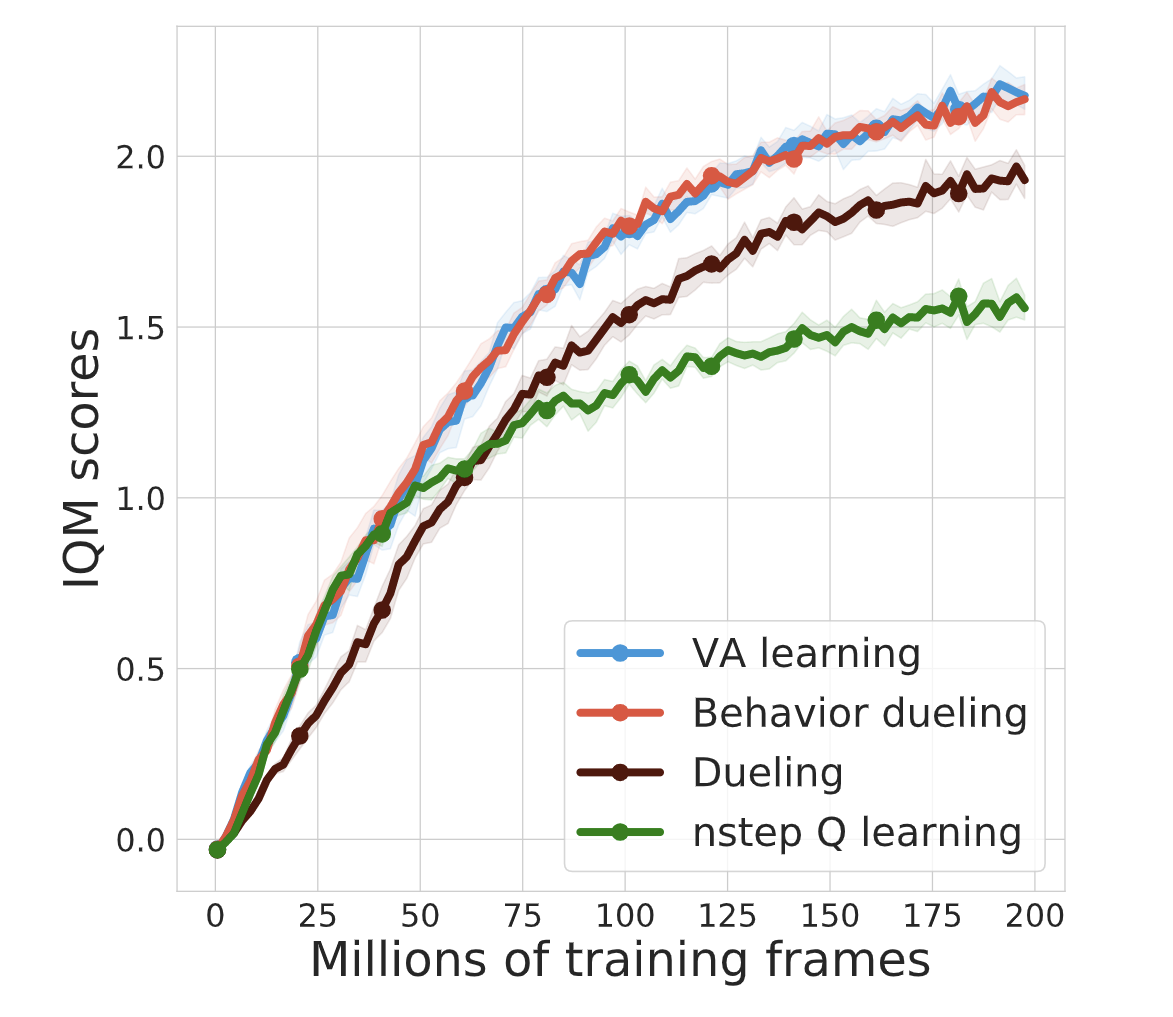
VA-learning as a more efficient alternative to Q-learning
Yunhao Tang, Rémi Munos, Mark Rowland, Michal Valko.
Arxiv, ICML 2023
VA-learning as a more sample efficient alternative to Q-learning, closely related to dueling architecture.
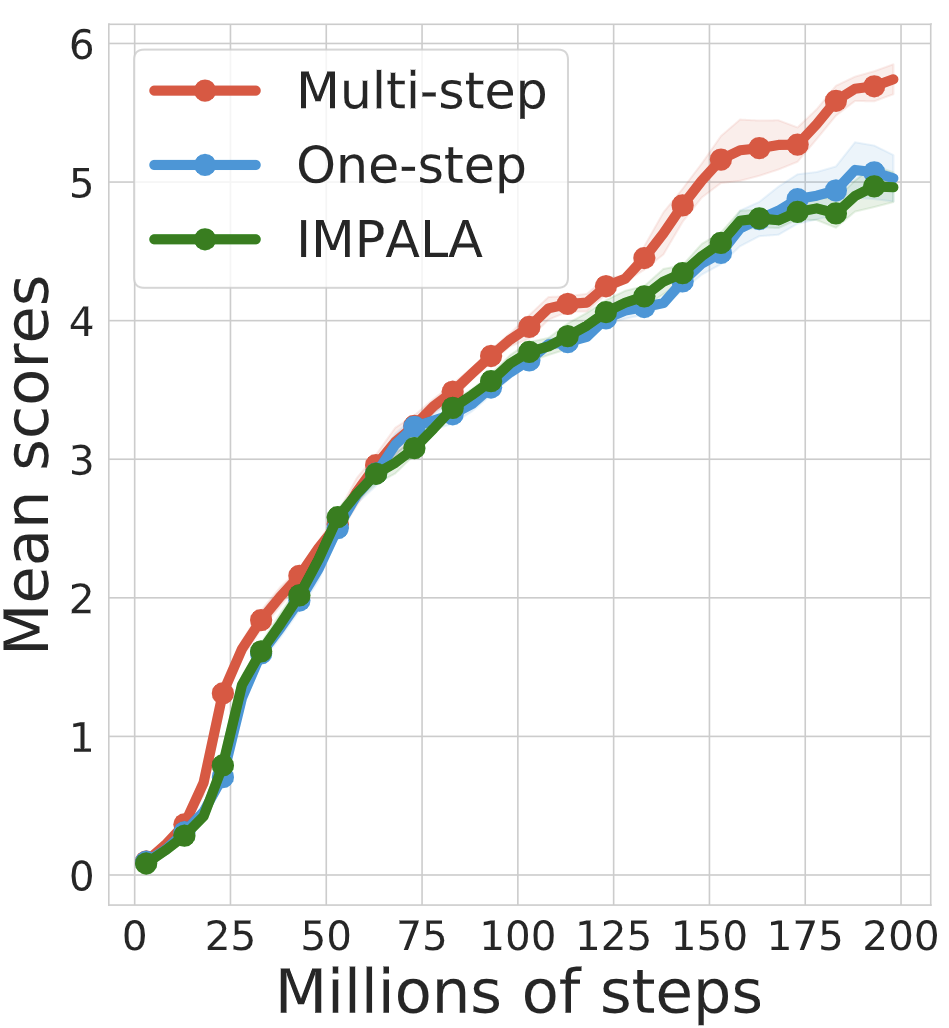
DoMo-AC: Doubly Multi-step Off-policy Actor-Critic Algorithm
Yunhao Tang*, Tadashi Kozuno*, Mark Rowland, Anna Harutyunyan, Rémi Munos, Bernardo Avila Pires, Michal Valko.
Arxiv, ICML 2023
An off-policy actor-critic algorithm based on multi-step policy improvement and evaluation.
Towards a better understanding of representation dynamics under TD-learning
Yunhao Tang, Rémi Munos.
Arxiv, ICML 2023
A characterization on how TD-learning learns representations.
Thomas Mesnard, Wenqi Chen, Alaa Saade, Yunhao Tang, Mark Rowland, Theophane Weber, Clare Lyle, Audrunas Gruslys, Michal Valko, Will Dabney, Georg Ostrovski, Eric Moulines, Rémi Munos.
Arxiv, ICML 2023, Oral
Efficient credit assignment should account for external factors outside of agent's control.
The Statistical Benefits of Quantile Temporal-Difference Learning for Value Estimation
Mark Rowland, Yunhao Tang, Clare Lyle, Rémi Munos, Marc G. Bellemare, Will Dabney.
Arxiv, ICML 2023
Quantile TD can outperform TD in mean value prediction.
Understanding Self-Predictive Learning for Reinforcement Learning
Yunhao Tang, Zhaohan Daniel Guo, Pierre Harvey Richemond, Bernardo Avila Pires, Yash Chandak, Rémi Munos, Mark Rowland, Mohammad Gheshlaghi Azar, Charline Le Lan, Clare Lyle, Andras Gyorgy, Shantanu Thakoor, Will Dabney, Bilal Piot, Daniele Calandriello, Michal Valko.
Arxiv, ICML 2023
Self-predictive learning is related to gradient-based spectral decomposition of the transition dynamics.
An Analysis of Quantile Temporal-Difference Learning
Mark Rowland, Rémi Munos, Mohammad Gheshlaghi Azar, Yunhao Tang, Georg Ostrovski, Anna Harutyunyan, Karl Tuyls, Marc G. Bellemare, Will Dabney.
Arxiv, JMLR
A first proof of the convergence of quantile TD-learning.
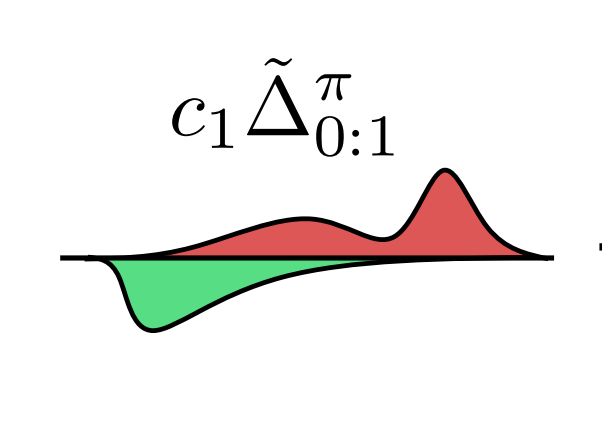
The Nature of Temporal Difference Errors in Multi-step Distributional Reinforcement Learning
Yunhao Tang, Mark Rowland, Rémi Munos, Bernardo Avila Pires, Will Dabney, Marc G. Bellemare.
Arxiv, NeurIPS 2022
Fundamental differences between value-based TD-learning and distributional TD-learning.
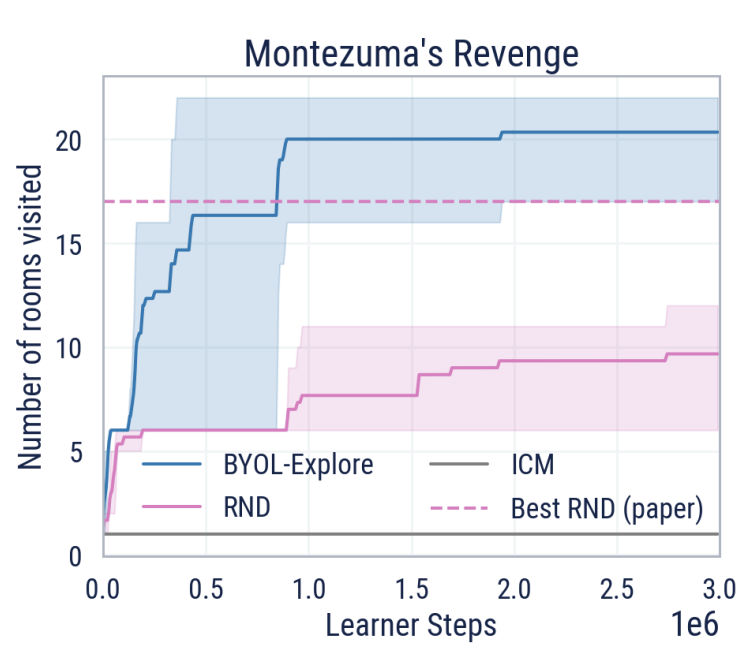
BYOL-Explore: Exploration by Bootstrapped Prediction
Zhaohan Daniel Guo*, Shantanu Thakoor*, Miruna Pislar*, Bernardo Avila Pires*, Florent Altche*, Corentin Tallec*, Alaa Saade, Daniele Calandriello, Jean-Bastien Grill, Yunhao Tang, Michal Valko, Rémi Munos, Mohammad Gheshlaghi Azar*, Bilal Piot*.
Arxiv, NeurIPS 2022
Self-prediction loss is a surprisingly useful signal for exploration.
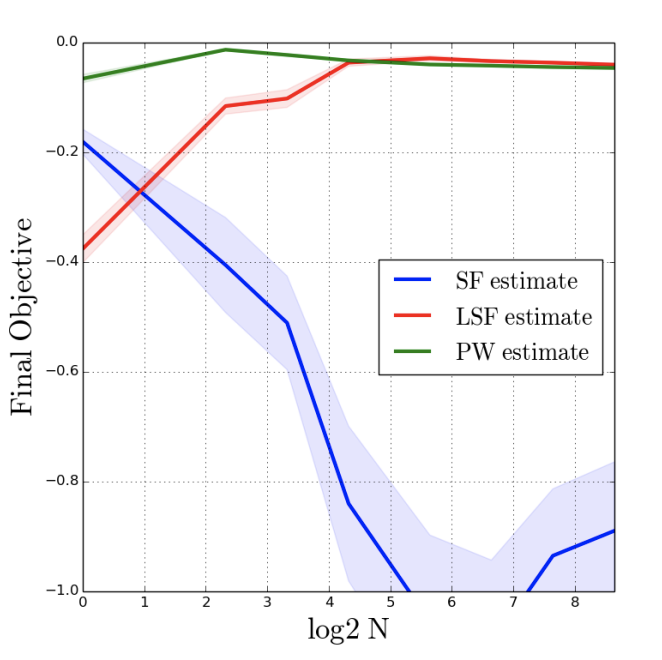
Biased Gradient Estimate with Drastic Variance Reduction for Meta Reinforcement Learning
Yunhao Tang.
arXiv, ICML 2022
Certain deliberate bias in gradient estimators could significantly reduce variance for meta RL.
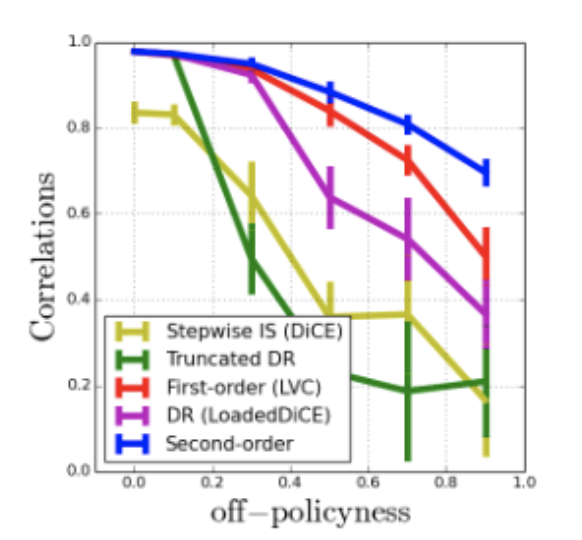
Unifying Gradient Estimators for Meta-Reinforcement Learning via Off-Policy Evaluation
Yunhao Tang*, Tadashi Kozuno*, Mark Rowland, Rémi Munos, Michal Valko.
A unifying framework for high-order derivatives of value functions via off-policy evaluation.
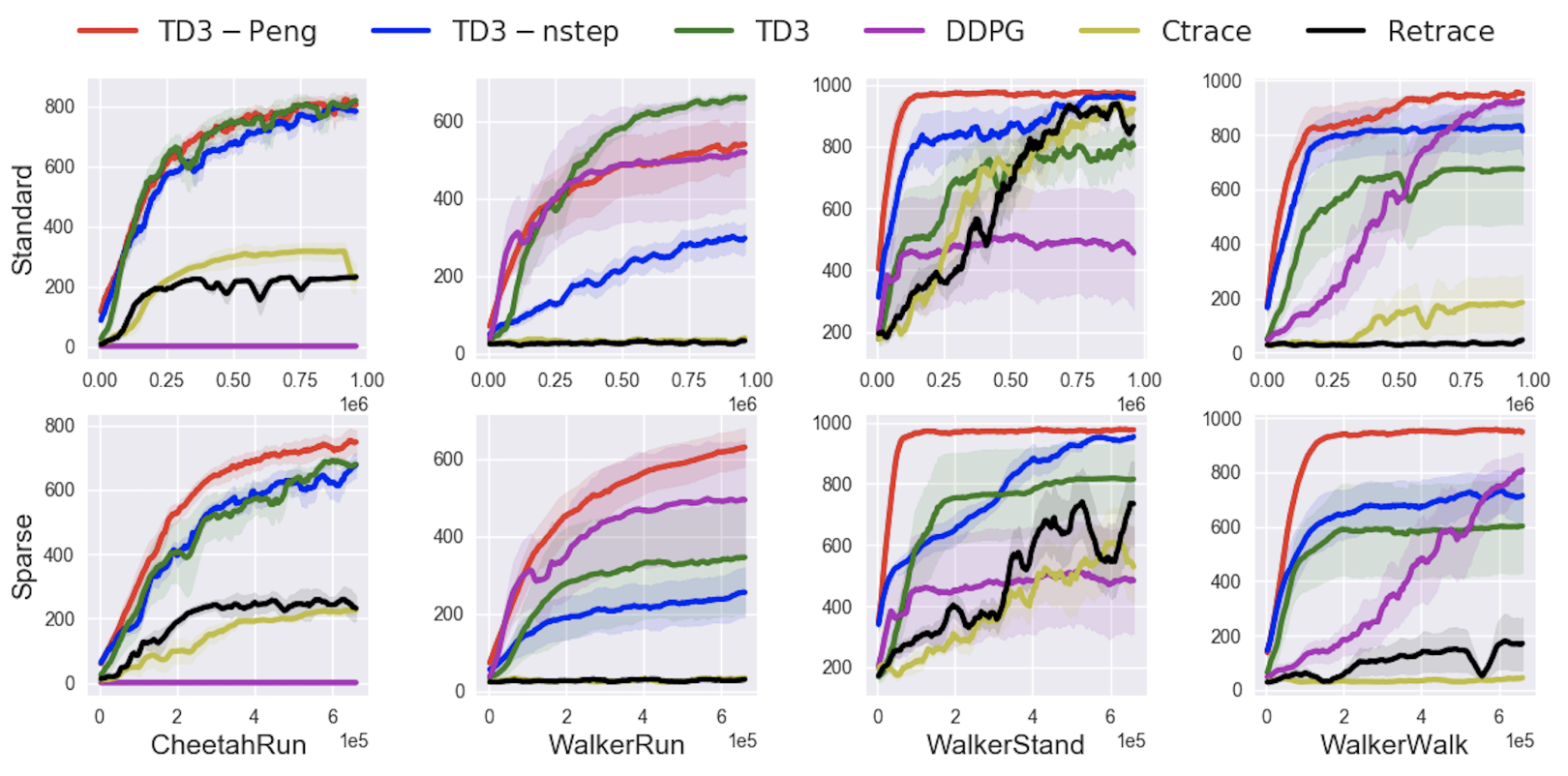
Revisiting Peng's Q(λ) for Modern Reinforcement Learning
Tadashi Kozuno*, Yunhao Tang*, Mark Rowland, Rémi Munos, Steven Kapturowski, Will Dabney, Michal Valko, David Abel.
Our analysis sheds light on why uncorrected updates should work in practice.
Hindsight Expectation Maximization for Goal-conditioned Reinforcement Learning
Yunhao Tang, Alp Kucukelbir.
Hindsight Expectation Maximization (hEM) combines supervised learning with hindsight goal sampling.

Self-Imitation Learning via Generalized Lower Bound Q-learning
Yunhao Tang.
We shed light on the connections between self-imitation learning and n-step Q-learning.
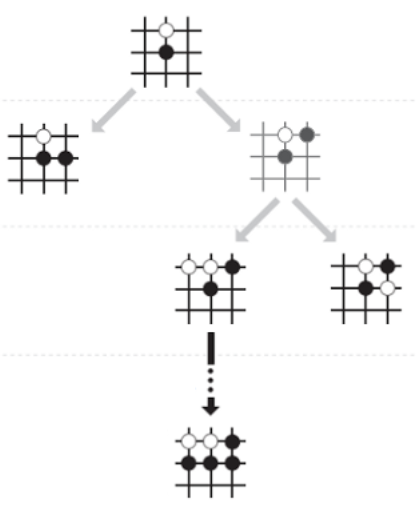
Monte-Carlo Tree Search as Regularized Policy Optimization
Jean-Bastien Grill*, Florent Altche*, Yunhao Tang*, Thomas Hubert, Michal Valko, Ioannis Antonoglou, Rémi Munos.
An interpretation of MCTS as policy optimization, leading to improvements over AlphaZero and MuZero.
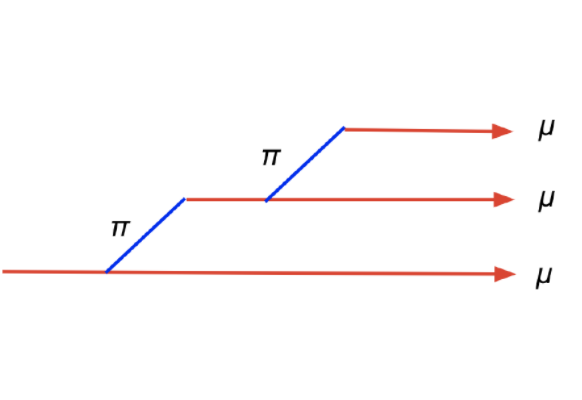
Taylor Expansion Policy Optimization
Yunhao Tang, Michal Valko, Rémi Munos.
arXiv / video / media 1 / media 2, ICML 2020
TayPO generalizes policy optimization objectives to high-order extensions for gains on large-scale distributed agents.
Reinforcement Learning for Integer Programming: Learning to Cut
Yunhao Tang, Shipra Agrawal, Yuri Faenza.
Cutting plane algorithms as sequential decision making for generic integer programming.