|
I am a researcher interested in reinforcement learning. Currently, I am a member of technical staff on the pre-training team at Anthropic. Before this, I spent some time working on reasoning at Mistral. Before that, I was at the Llama research team. I spearheaded the prototype and algorithmic recipes for online RL and, as part of a small team, scaled the training to Llama 3.3-4. I also worked on post-training for reasoning. Et avant ça, I spent a few years at DeepMind London, where I was a core contributor to Gemini v1-1.5 post-training with a focus on tool use and agent. I also researched various aspects of deep RL algorithms and systems. Previously, I was a two-time intern at DeepMind Paris hosted by Rémi Munos. I obtained my PhD at Columbia University in New York City. |

|
|
|
Besides building frontier models, I also enjoy researching science. My past work focused on the understanding and developments of deep reinforcement learning algorithms and systems, spanning the following non-exhaustive list of topics
See here for the full list of publications. |
|
|
|
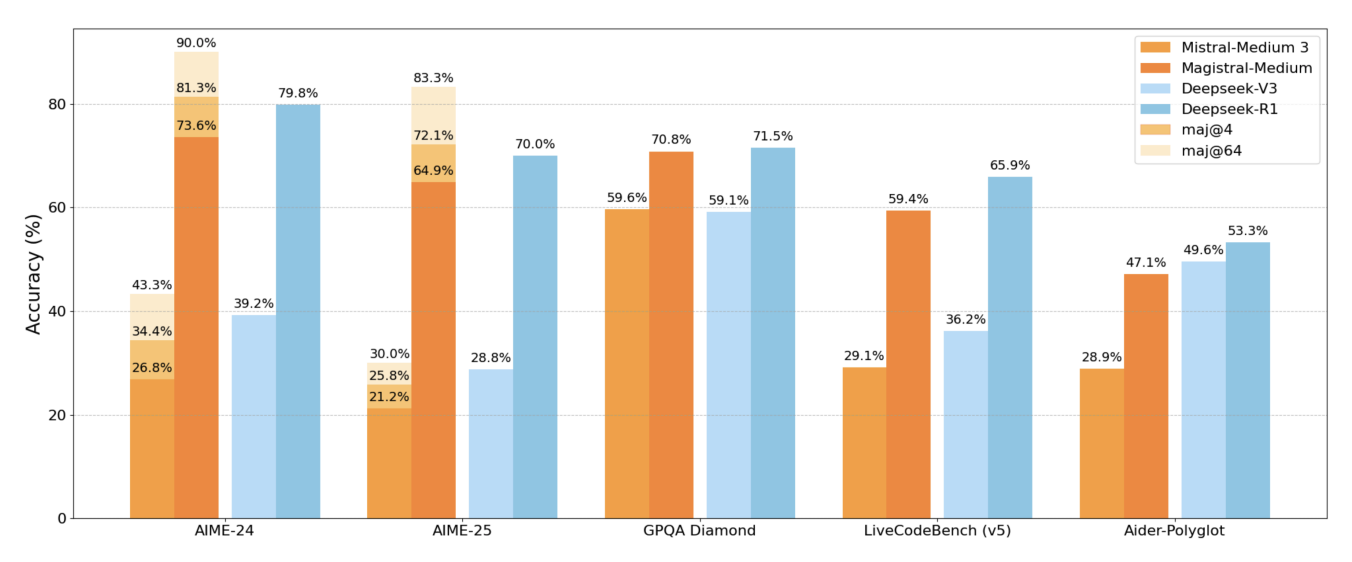
Mistral team, Magistral 1.2 is a major improvement over predecessors, achieving highly competitive performance as other frontier reasoning models. |
|
Mistral team, Arxiv, Magistral is the first reasoning model by Mistral. The technical report documents valuable practical insights for reasoning focused post-training. All credits to the team. |
|
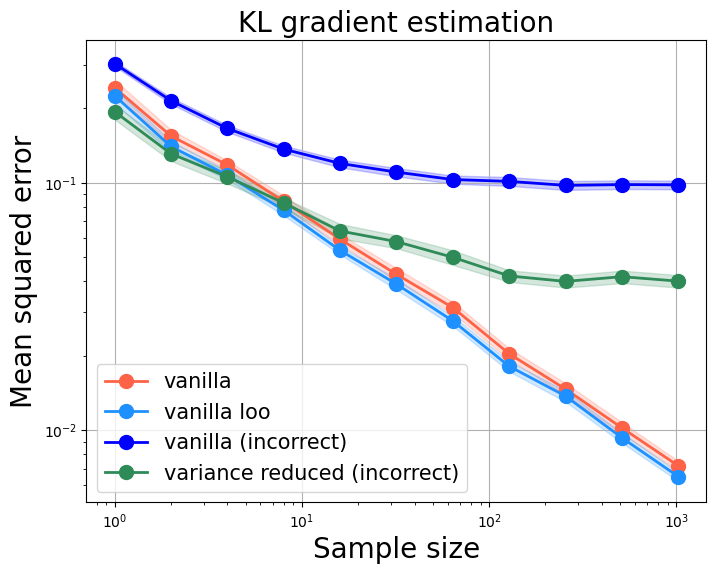
Yunhao Tang, Rémi Munos Arxiv, Tinker citation We highlight two pitfalls on building KL gradient estimate for RL applications, as well as their practical impact. Such pitfalls are commonly observed in recent RL implementations for LLM fine-tuning and research papers. |
|
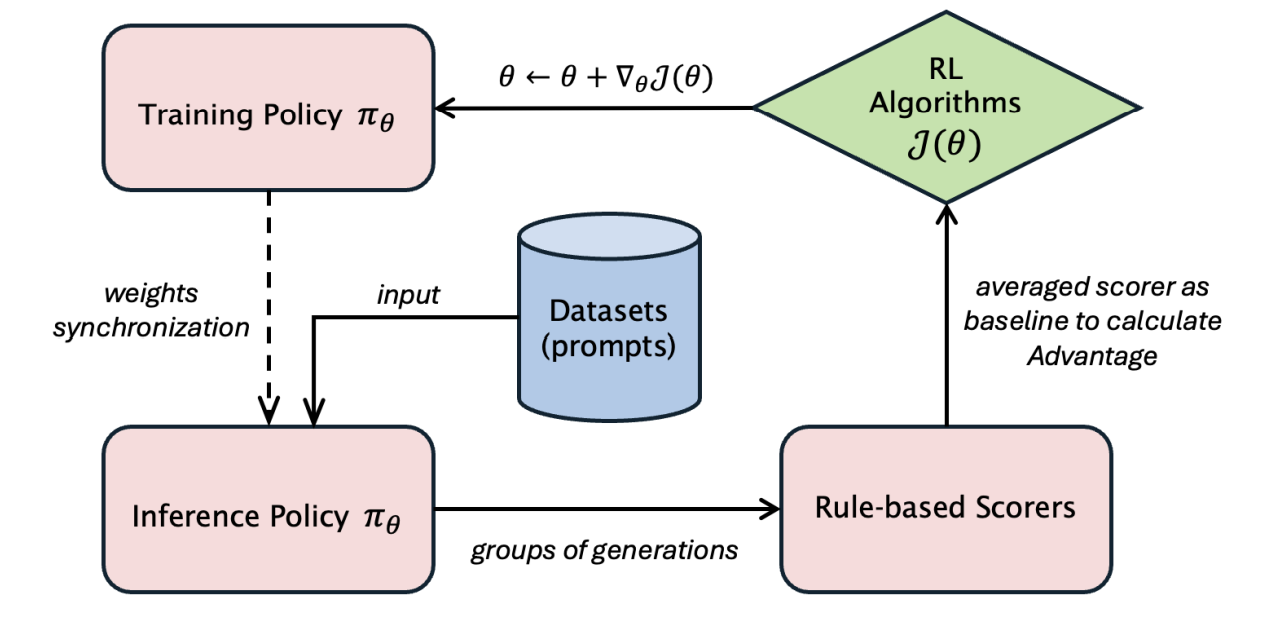
Bo Wu*, Sid Wang*, Yunhao Tang*, Jia Ding*, et al Arxiv, LlamaRL is the first distributed asynchronous off-policy RL stack that powers large-scale Llama training internal to Llama research. In this report, we detail the key infra and algorithmic designs that help stabilize RL training of LLM at scale. Example applications include Llama 3.3, Llama 4 and their future extended releases. |
|
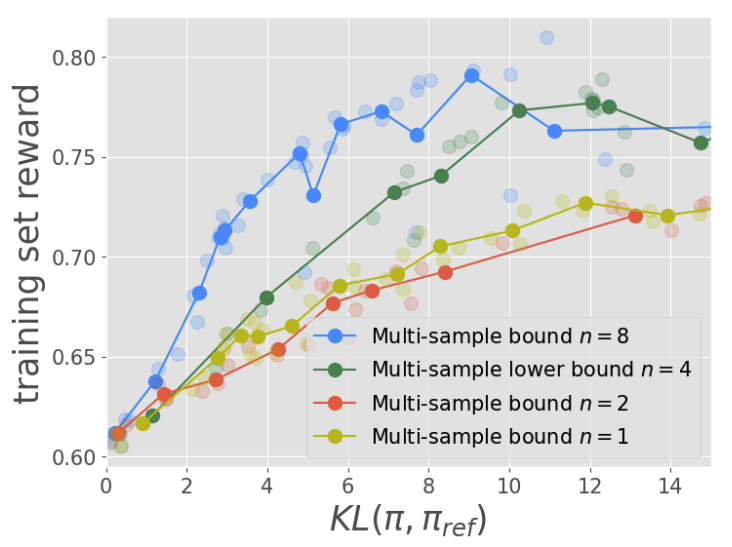
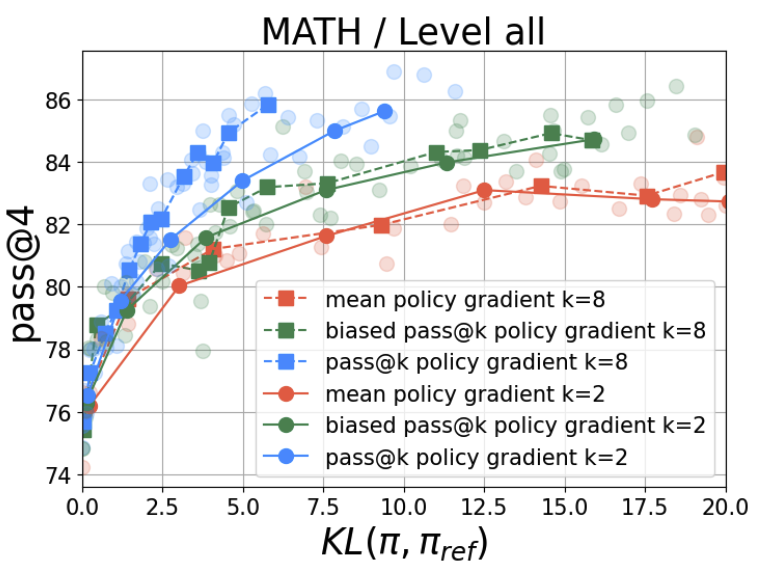
Yunhao Tang, Sid Wang, Lovish Madaan, Rémi Munos Arxiv, NeurIPS 2025 We extend RL training beyond verifiable reward with Jensen's Evidence lower bound Policy Optimization (JEPO). JEPO can train on long-form data with no easy verifier and is compatible with large-scale training stacks. Our work unlocks a new paradigm for fine-tuning models with richer data sources. |
|
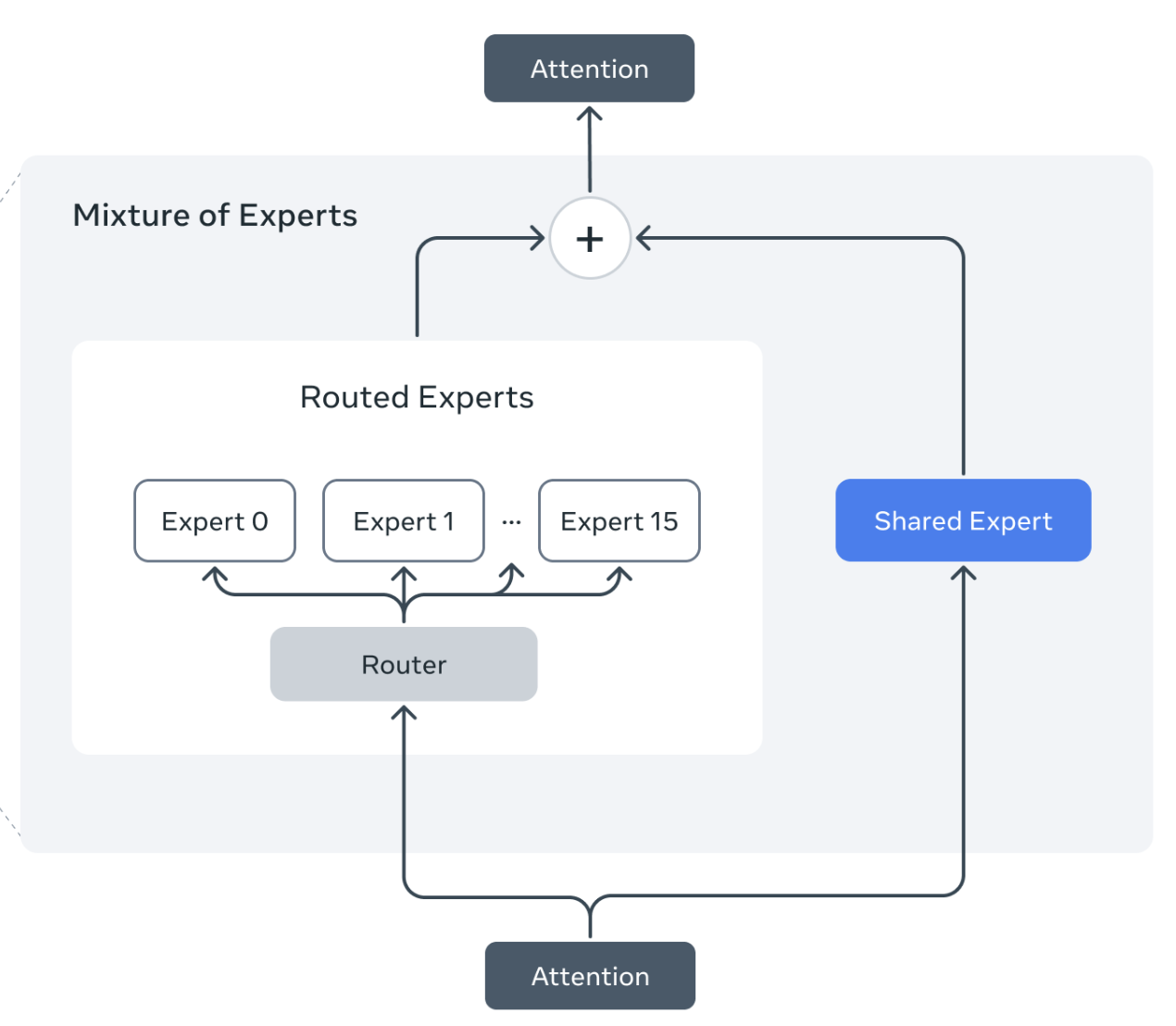
Llama research team Technical notes, Llama 4 MoEs present a unique set of challanges for RL training, demanding both algorithmic and infra improvements. |
|
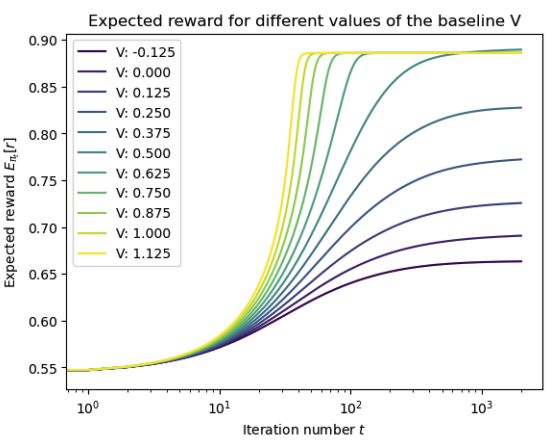
Charles Arnal, Gaëtan Narozniak, Vivien Cabannes, Yunhao Tang, Julia Kempe, Rémi Munos Arxiv, NeurIPS 2025 We analyze an asymetric version of REINFORCE algorithm, which naturally appears in the off-policy case. The baseline function plays a key role here beyond variance reduction. |
|
Yunhao Tang*, Kunhao Zheng*, Gabriel Synnaeve, Rémi Munos* Arxiv, ICML 2025 We find that simple inference aware finetuning algorithms can greatly improve test time performance, as evaluated on a large suite of code generation and reasoning tasks. |
|
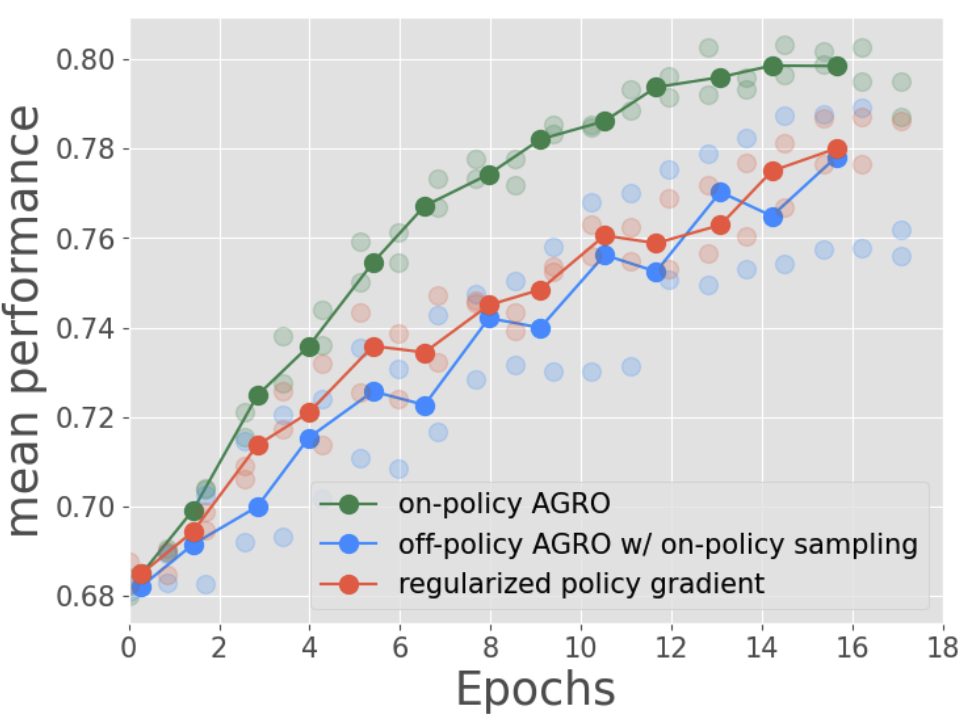
Yunhao Tang*, Taco Cohen, David W. Zhang, Michal Valko, Rémi Munos* Arxiv, AISTATS 2026 We propose Any Generation Reward Optimization (AGRO), a fine-tuning algorithm that leverages data from arbitrary data sources for model alignment. |
|
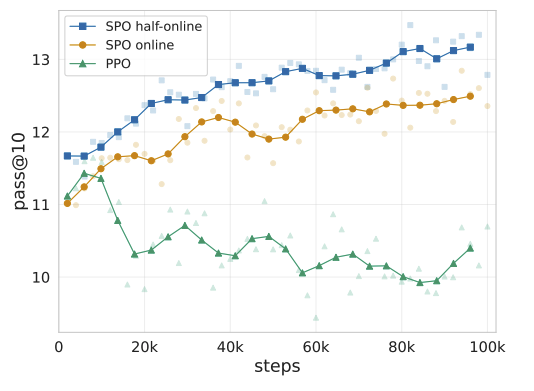
Taco Cohen*, David W. Zhang*, Kunhao Zheng, Yunhao Tang, Rémi Munos, Gabriel Synnaeve Arxiv, We find that using soft policy optimization - a novel policy optimization method inspired by regularized RL and specialized to sequence learning - outperforms PPO on code generation tasks. |
|
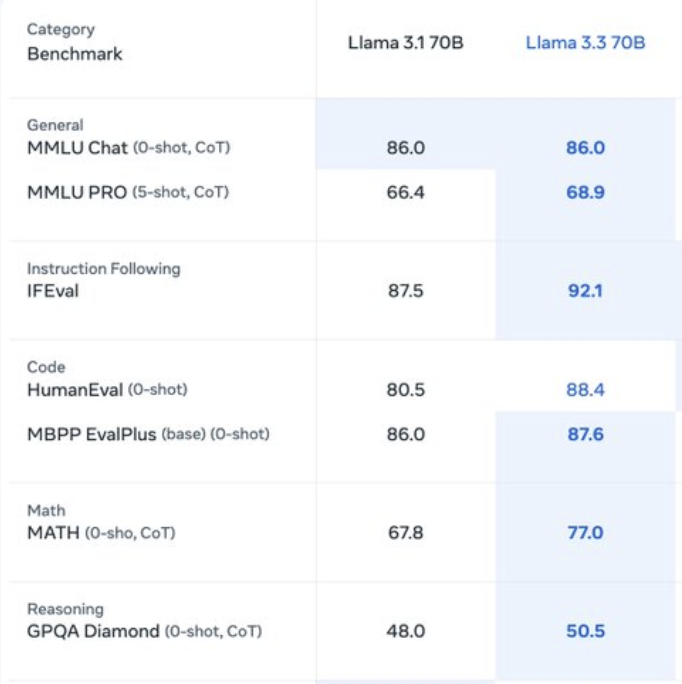
Llama research team Llama 3.3 is the first Llama model trained with a large-scale RL stack, reasonable in model size while approaching the performance of Llama 3.1 405B in certain domains. |
|
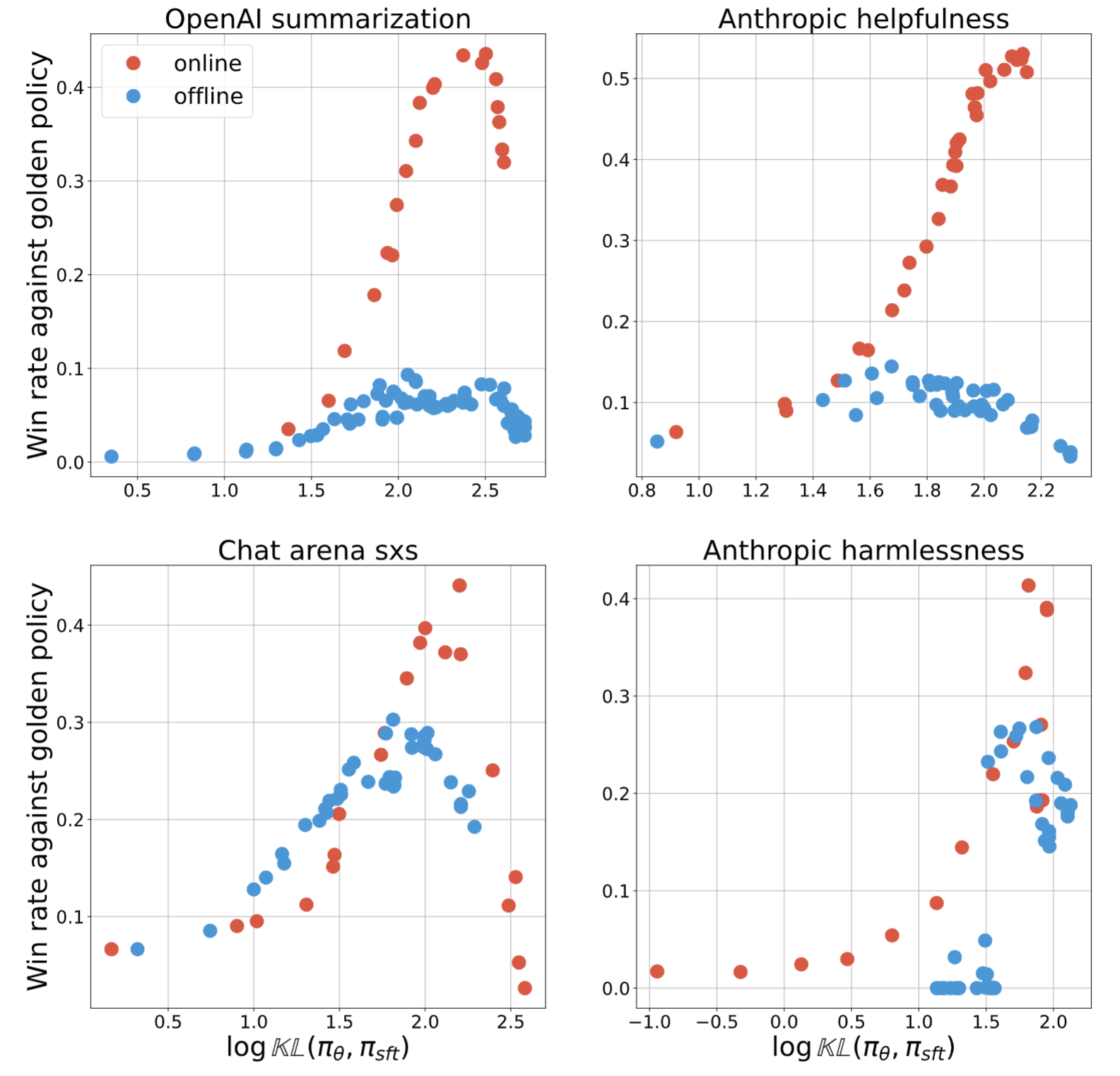
Yunhao Tang, Daniel Guo, Zeyu Zheng, Daniele Calandriello, Yuan Cao, Eugene Tarassov, Rémi Munos, Bernardo Avila Pires, Michal Valko, Yong Cheng, Will Dabney Arxiv, Is online RL really necessary for AI alignment, or do offline algorithms suffice? The answer seems to be yes according to our careful ablations. |
|
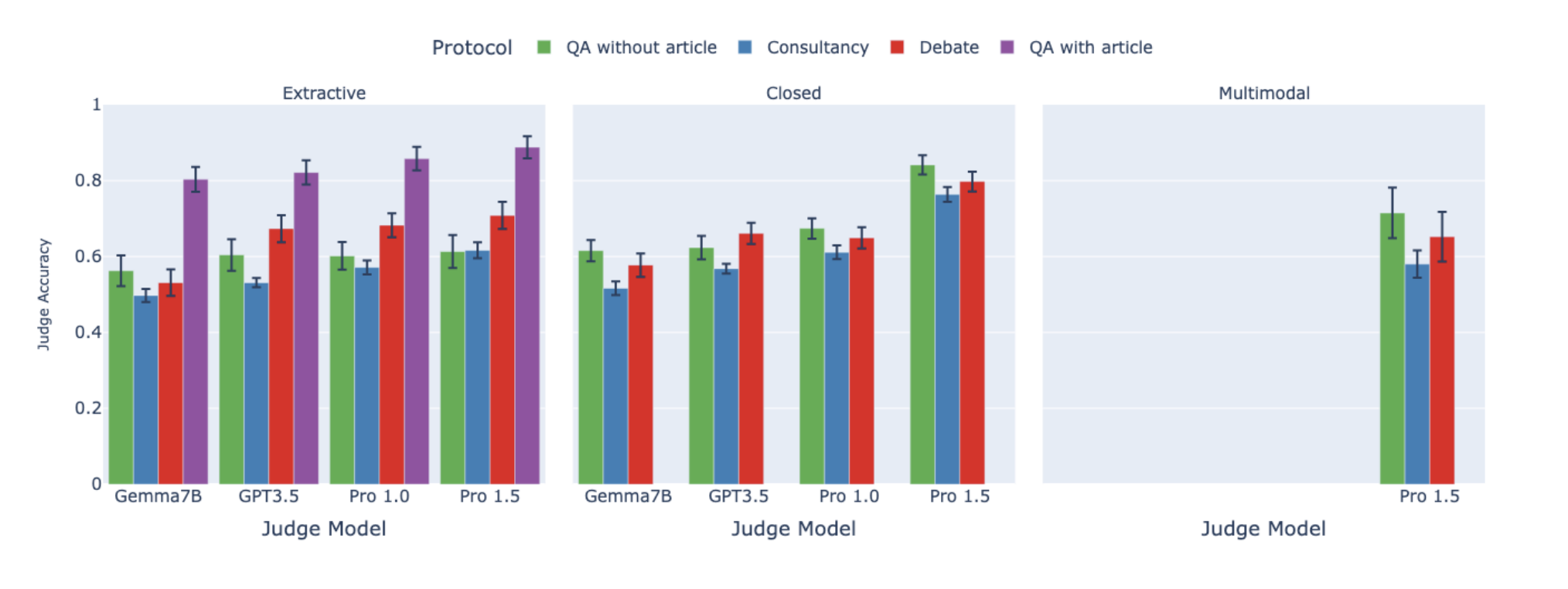
Zachary Kenton*, Noah Y. Siegel*, Janos Kramar, Jonah Brown-Cohen, Samuel Albanie, Jannis Bulian, Rishabh Agarwal, David Lindner, Yunhao Tang, Noah D. Goodman, Rohin Shah Arxiv, NeurIPS 2024 We have benchmarked important existing scalable-oversight protocols in a comprehensive suite of QA tasks, opening the path for further future investigation. |
|
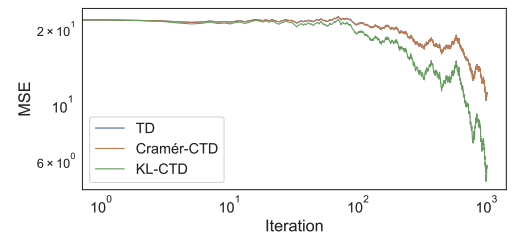
Tyler Kastner, Mark Rowland, Yunhao Tang, Murat A. Erdogdu, Amir M. Farahmand ICML 2025, We seek to close another important theory-practice gap in distributional RL - the KL-divergence based implementation of categorical projection. |
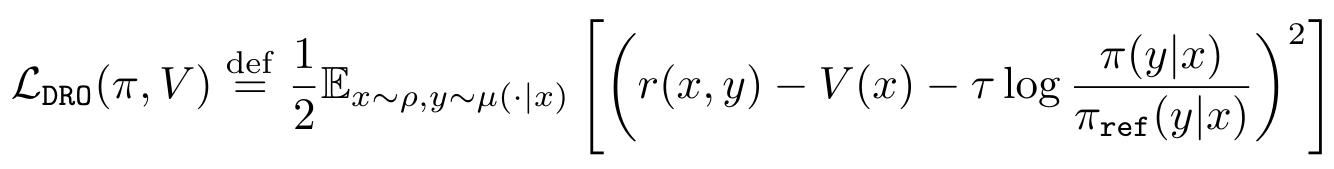
|
Pierre Harvey Richemond, Yunhao Tang, Daniel Guo, Daniele Calandriello, Mohammad Gheshlaghi Azar, Rafael Rafailov, Bernardo Avila Pires, Eugene Tarassov, Lucas Spangher, Will Ellsworth, Aliaksei Severyn, Jonathan Mallinson, Lior Shani, Gil Shamir, Rishabh Joshi, Tianqi Liu, Rémi Munos, Bilal Piot Arxiv, When human feedback is pointwise rather than pairwise, we propose direct reward optimization (DRO) as the alignment algorithm. |
|
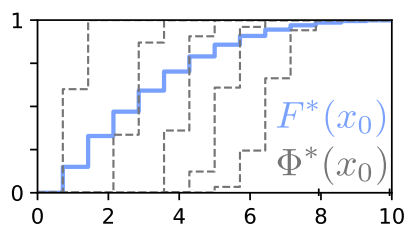
Mark Rowland, Li Kevin Wenliang, Rémi Munos, Clare Lyle, Yunhao Tang, Will Dabney Arxiv, NeurIPS 2024 We show a minimax optimal model based algorithm for distributional RL, relying on a new class of categorical distributional Bellman equations. |
|
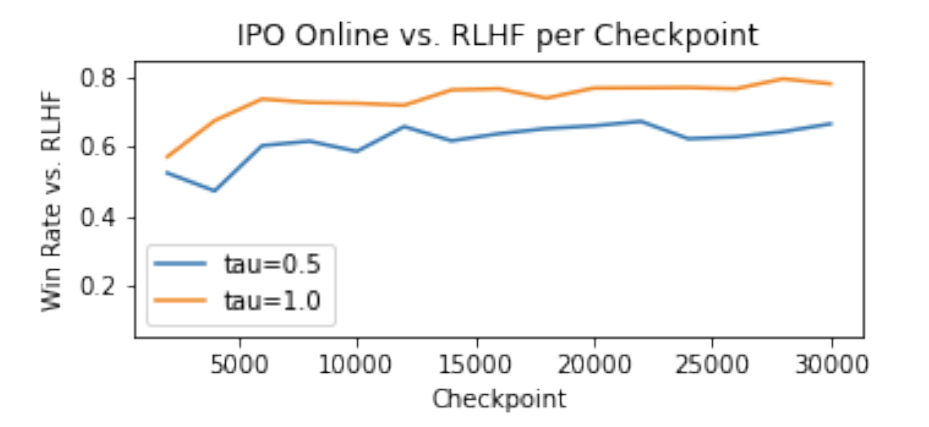
Daniele Calandriello, Daniel Guo, Rémi Munos, Mark Rowland, Yunhao Tang, Bernardo Avila Pires, Pierre Harvey Richemond, Charline Le Lan, Michal Valko, Tianqi Liu, Rishabh Joshi, Zeyu Zheng, Bilal Piot Arxiv, ICML 2024 Online preference optimization as an alignment technique turns out to be intimately related to Nash equilibrium, besides being a competitive algorithm for RLHF. |
|
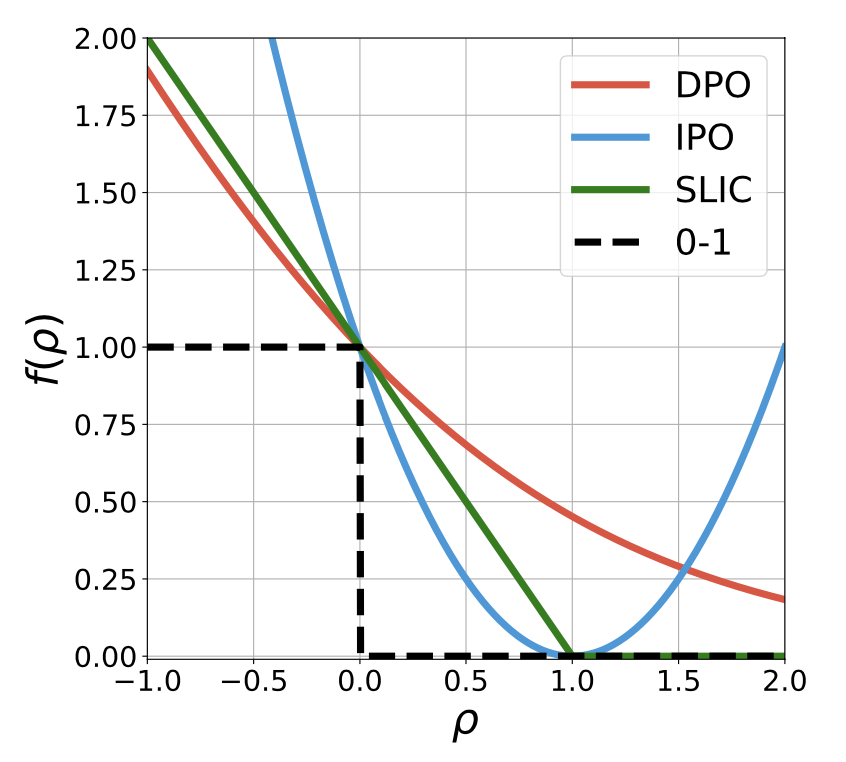
Yunhao Tang, Daniel Zhaohan Guo, Zeyu Zheng, Daniele Calandriello, Rémi Munos, Mark Rowland, Pierre Harvey Richmond, Michal Valko, Bernardo Avila Pires, Bilal Piot Arxiv, ICML 2024 GPO unifies alignment algorithms such as DPO, IPO and SLiC as special cases. The insight, interestingly, is based on classic literature on convex losses for binary classification. At the end of the day, all algorithmic variants have similar performance-regularization trade-off though their natural strengths of regularization differ. |
|
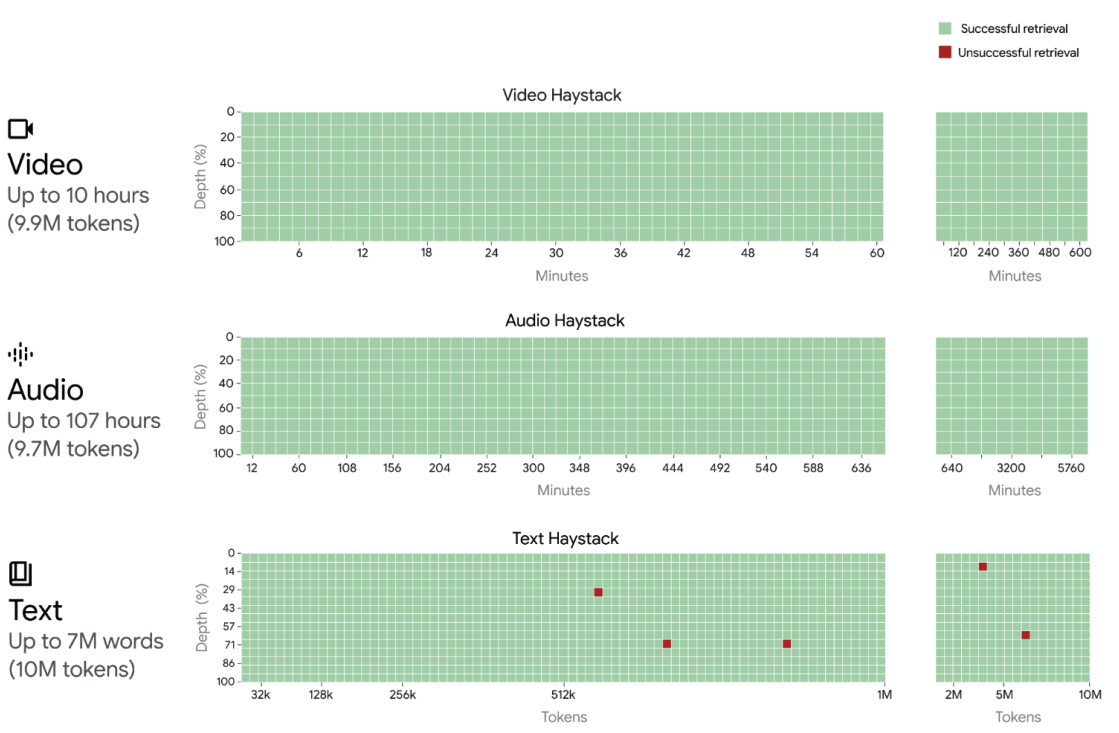
Gemini team, Google DeepMind. Arxiv, Long context allows for exciting use cases such as tool use and agentic workflows to complete more complex tasks. |

|
Gemini team, Google DeepMind. Tech report Arxiv, One of the most powerful multi-modal large language models thus far in the world. |
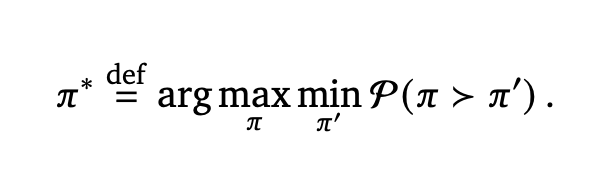
|
Rémi Munos*, Michal Valko*, Daniele Calandriello*, Mohammad Gheshlaghi Azar*, Mark Rowland*, Daniel Guo*, Yunhao Tang*, Matthieu Geist*, Thomas Mesnard, Andrea Michi, Marco Selvi, Sertan Girgin, Nikola Momchev, Olivier Bachem, Daniel J. Mankowitz, Doina Precup and Bilal Piot* Arxiv, ICML 2024 In aligning large language models, we search for Nash Equilibrium naturally defined via the pairwise human feedback. This approach is more general purpose, imposes fewer assumptions on reward modeling, and performs better than canonical RLHF. |
|
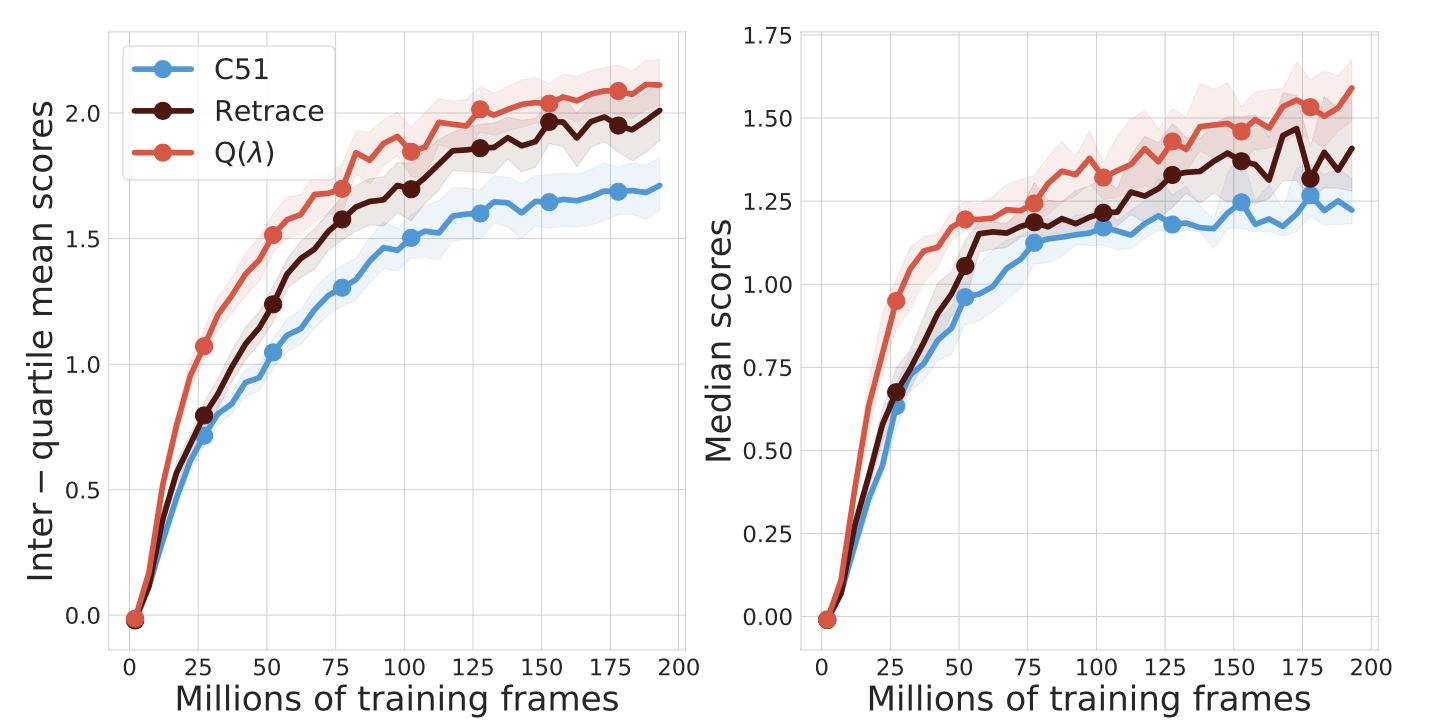
Yunhao Tang, Mark Rowland, Rémi Munos, Bernardo Avila Pires, Will Dabney Arxiv, AISTATS 2026 We introduce another addition to the family of off-policy distributional RL algorithms, importantly, without the need for importance sampling. |
|
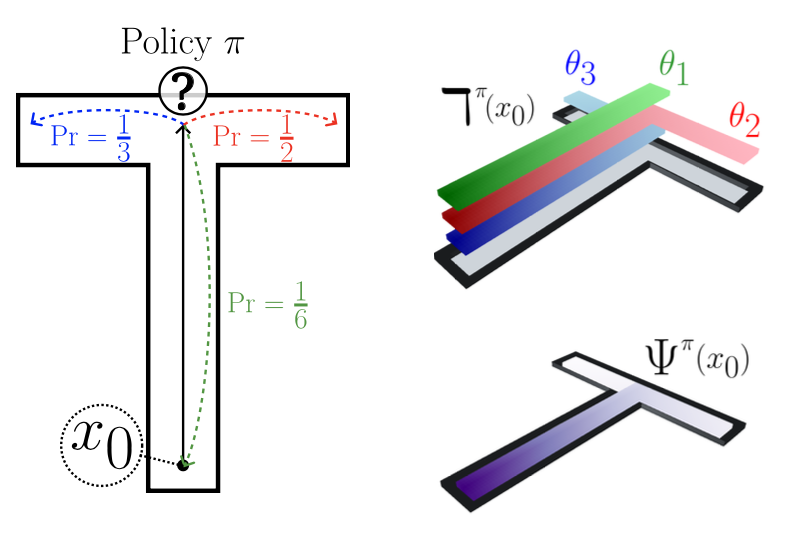
Harley Wiltzer*, Jesse Farebrother*, Arthur Greton, Yunhao Tang, André Barreto, Will Dabney, Marc G. Bellemare, Mark Rowland Arxiv, ICML 2024 We shed light on what distributional equivalence of successor representations look like, and the algorithmic applications arising from the insights. |
|
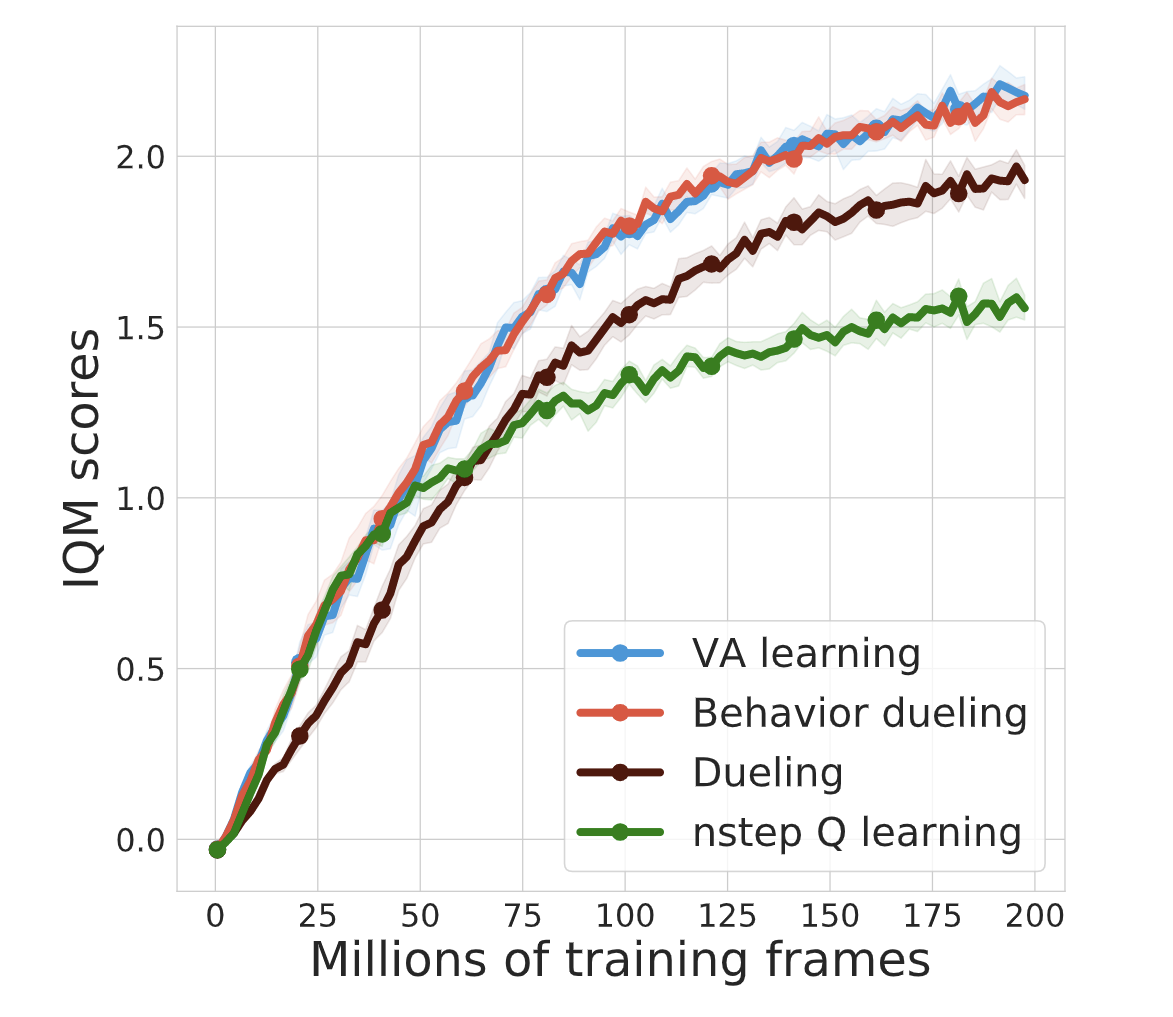
Yunhao Tang, Rémi Munos, Mark Rowland, Michal Valko Arxiv, ICML 2023 We propose VA-learning as a more sample efficient alternative to Q-learning. The sample efficiency stems from the value sharing between different actions. Intriguingly, VA-learning closely relates to dueling architecture. |
|
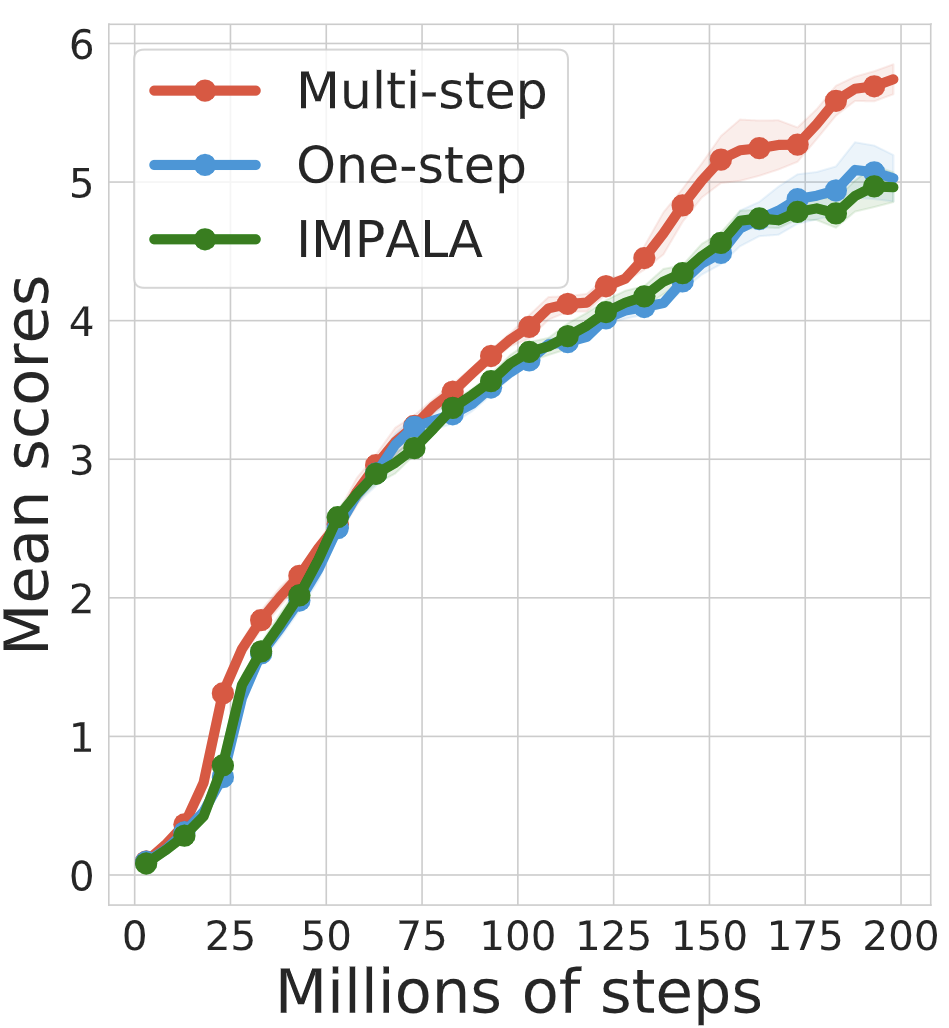
Yunhao Tang*, Tadashi Kozuno*, Mark Rowland, Anna Harutyunyan, Rémi Munos, Bernardo Avila Pires, Michal Valko Arxiv, ICML 2023 We design an off-policy actor-critic algorithm based on multi-step policy improvement and policy evaluation. This algorithm improves state-of-the-art IMPALA baseline. |
|
Yunhao Tang, Rémi Munos Arxiv, ICML 2023 We provide a characterization on how TD-learning learns representations, relating random reward based TD-learning with spectral decomposition of the transition matrix. |
|
Thomas Mesnard, Wenqi Chen, Alaa Saade, Yunhao Tang, Mark Rowland, Theophane Weber, Clare Lyle, Audrunas Gruslys, Michal Valko, Will Dabney, Georg Ostrovski, Eric Moulines, Rémi Munos Arxiv, ICML 2023, Oral Efficient credit assignment should account for external factors outside of agent's control, or more informally, the level of luck. We formalize such intuitions into quantile credit assignment. |
|
Mark Rowland, Yunhao Tang, Clare Lyle, Rémi Munos, Marc G. Bellemare, Will Dabney Arxiv, ICML 2023 We show that in certain cases quantile TD outperforms TD in mean value prediction. This hints at a general potential of distributional RL to outperform mean-based RL at its own game. |
|
Yunhao Tang, Zhaohan Daniel Guo, Pierre Harvey Richemond, Bernardo Avila Pires, Yash Chandak, Rémi Munos, Mark Rowland, Mohammad Gheshlaghi Azar, Charline Le Lan, Clare Lyle, Andras Gyorgy, Shantanu Thakoor, Will Dabney, Bilal Piot, Daniele Calandriello, Michal Valko Arxiv, ICML 2023 Self-predictive learning is a popular representation learning algorithm in RL, which learns a latent representation by predicting (bootstrapping) its own future latents. Intuitively, the algorithm should not work as it can collapse to trivial solutions. We identify algorithmic components to prevent the collapse and show that self-preditive learning is related to gradient-based spectral decomposition of the transition dynamics. |
|
Mark Rowland, Rémi Munos, Mohammad Gheshlaghi Azar, Yunhao Tang, Georg Ostrovski, Anna Harutyunyan, Karl Tuyls, Marc G. Bellemare, Will Dabney JMLR Arxiv, We provide a first proof of the convergence of quantile TD-learning, a distributional RL algorithm that drives multiple recent empirical breakthroughs. |
|
Yunhao Tang, Mark Rowland, Rémi Munos, Bernardo Avila Pires, Will Dabney, Marc G. Bellemare Arxiv, NeurIPS 2022 We identify a few intriguing and fundamental differences between value-based TD-learning and distributional TD-learning. |
|
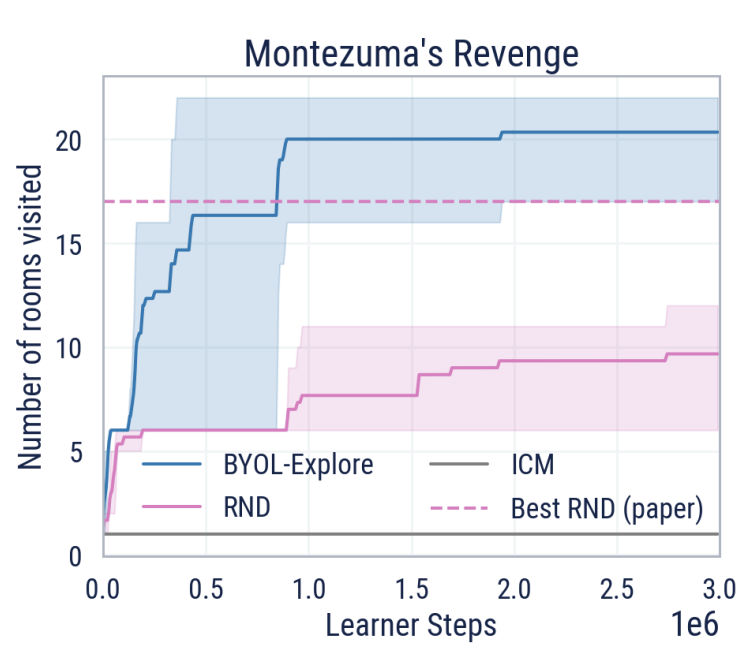
Zhaohan Daniel Guo*, Shantanu Thakoor*, Miruna Pislar*, Bernardo Avila Pires*, Florent Altche*, Corentin Tallec*, Alaa Saade, Daniele Calandriello, Jean-Bastien Grill, Yunhao Tang, Michal Valko, Rémi Munos, Mohammad Gheshlaghi Azar*, Bilal Piot* Arxiv, NeurIPS 2022 We find that self-prediction loss is a surprisingly useful signal for exploration in extremely challenging deep RL domains. Our method: BYOL-explore, partially cracks a wide range of extremely hard exploration problems much more efficiently than prior methods. |
|
Yunhao Tang International Conference on Machine Learning (ICML), Baltimore, USA, 2022 arXiv We find that certain deliberate bias in gradient estimators could significantly reduce variance for meta RL. |
|
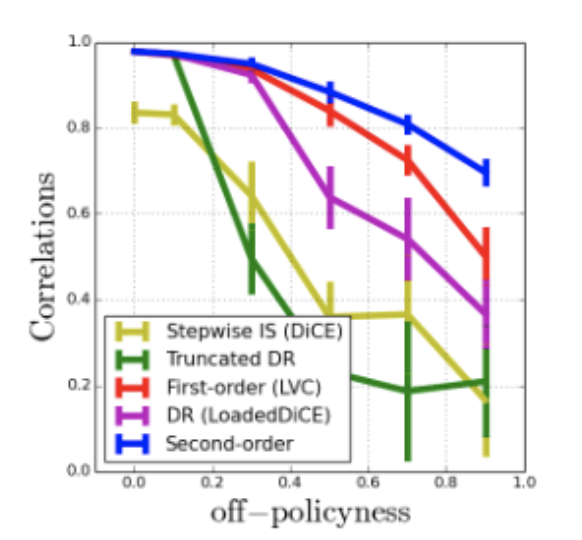
Yunhao Tang*, Tadashi Kozuno*, Mark Rowland, Rémi Munos, Michal Valko Neural Information Processing Systems (NeurIPS), Virtual, 2021 arXiv Code How to estimate high-order derivatives of value functions? We propose a unifying framework with off-policy evaluation. Direct differentiations of off-policy estimates produce estimates to high-order derivatives of value functions, and instantiate many prior methods as special cases. |
|
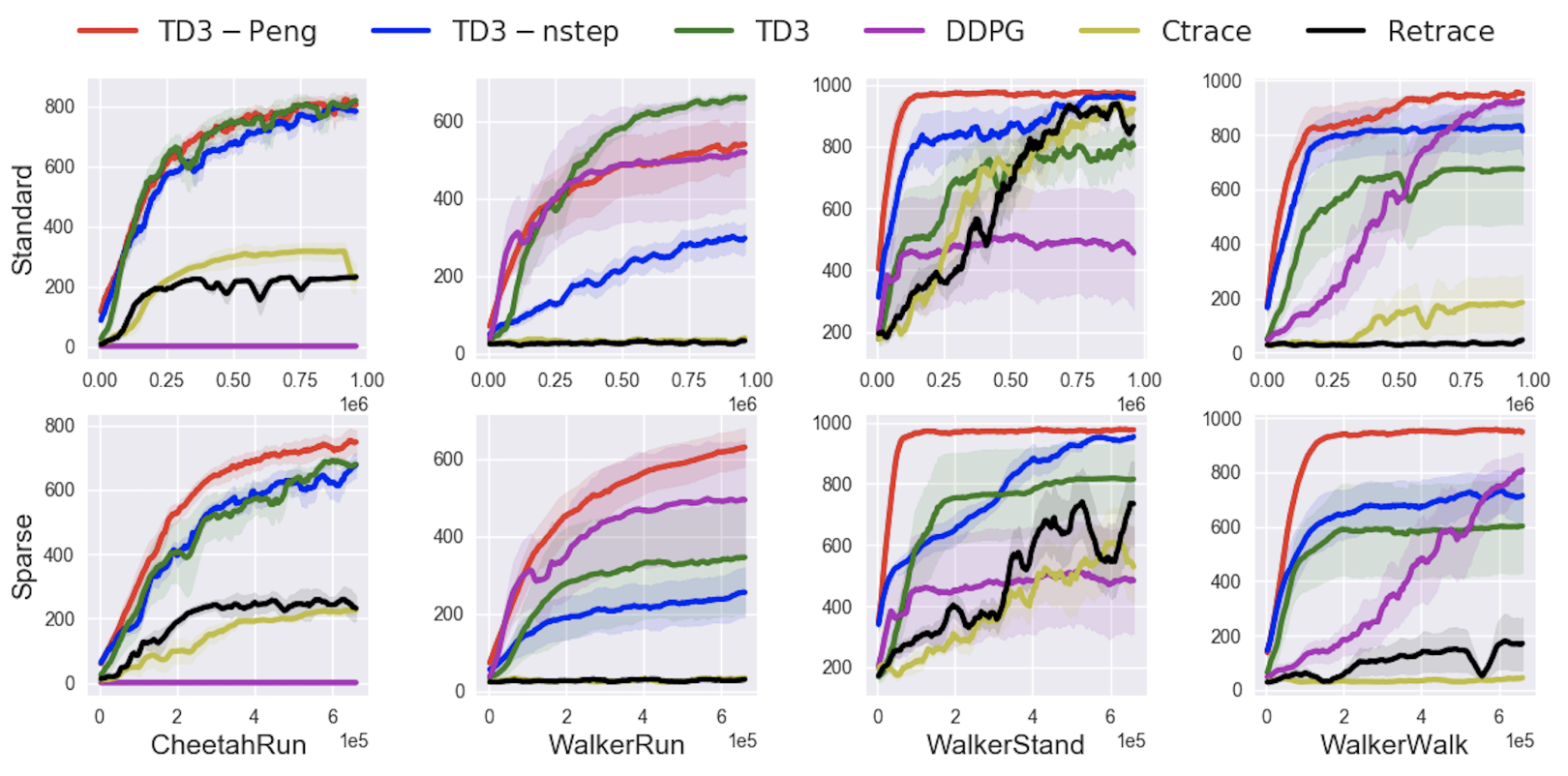
Tadashi Kozuno*, Yunhao Tang*, Mark Rowland, Rémi Munos, Steven Kapturowski, Will Dabney, Michal Valko, David Abel International Conference on Machine Learning (ICML), Virtual, 2021 ArXiv Code Uncorrected multi-step updates such as n-step Q-learning are ubiquitous in modern deep RL practices. We revisit Peng's Q($\lambda$), a classic uncorrected multi-step variant. Our analysis sheds light on why uncorrected updates should work in practice. The empirical result also suggests significant gains on benchmark tasks. |
|
Yunhao Tang, Alp Kucukelbir International Conference on Artificial Intelligence and Statistics (AISTATS), Virtual, 2021 paper / arXiv We propose Hindsight Expectation Maximization (hEM), an EM algorithm for goal-conditioned RL problem which combines supervised learning through the M-step and hindsight goal sampling through the E-step. We also make an intimate connection between hindsight replay and importance sampling for rare event simulations. |

|
Yunhao Tang Neural Information Processing Systems (NeurIPS), Vancouver, Canada, 2020 paper / arXiv Why is self-imitation learning efficient? We shed light on its connections to n-step Q-learning and show that part of its gains might be attributed to trade-offs in RL operators. We also propose a n-step extension of self-imitation learning which incorporates the strengths of both n-step updates and lower-bound learning. |
|
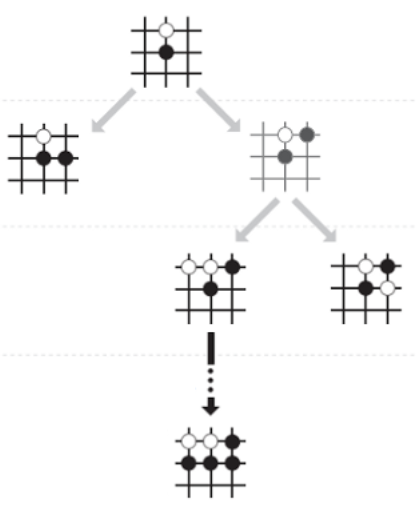
Jean-Bastien Grill*, Florent Altche*, Yunhao Tang*, Thomas Hubert, Michal Valko, Ioannis Antonoglou, Rémi Munos International Conference on Machine Learning (ICML), Vienna, Austria, 2020 paper / arXiv / video We establish an interpretation of MCTS as policy optimization. This interpretation leads to algorithmic variants which naturally improve over MCTS-based baselines such as AlphaZero and MuZero. |
|
Yunhao Tang, Michal Valko, Rémi Munos International Conference on Machine Learning (ICML), Vienna, Austria, 2020 paper / arXiv / video / media 1 / media 2 We estabilish the intimate connections between trust region policy search and off-policy evaluation. The new algorithm TayPO generalizes policy optimization objectives to high-order extentions which leads to gains on large-scale distributed agents. |
|
Yunhao Tang, Shipra Agrawal, Yuri Faenza International Conference on Machine Learning (ICML), Vienna, Austria, 2020 paper / arXiv / video We formulate cutting plane algorithms as a sequential decision making problem for generic integer pgroamming. The cutting plane agent learned via RL improves over human-designed heuristics and benfits downstream applications such as branch-and-cut. |