Mistral team.
2025
Magistral 1.2 is a major improvement over predecessors, achieving highly competitive performance as other frontier reasoning models.
I made core contributions to the following models.
Mistral team.
2025
Magistral 1.2 is a major improvement over predecessors, achieving highly competitive performance as other frontier reasoning models.
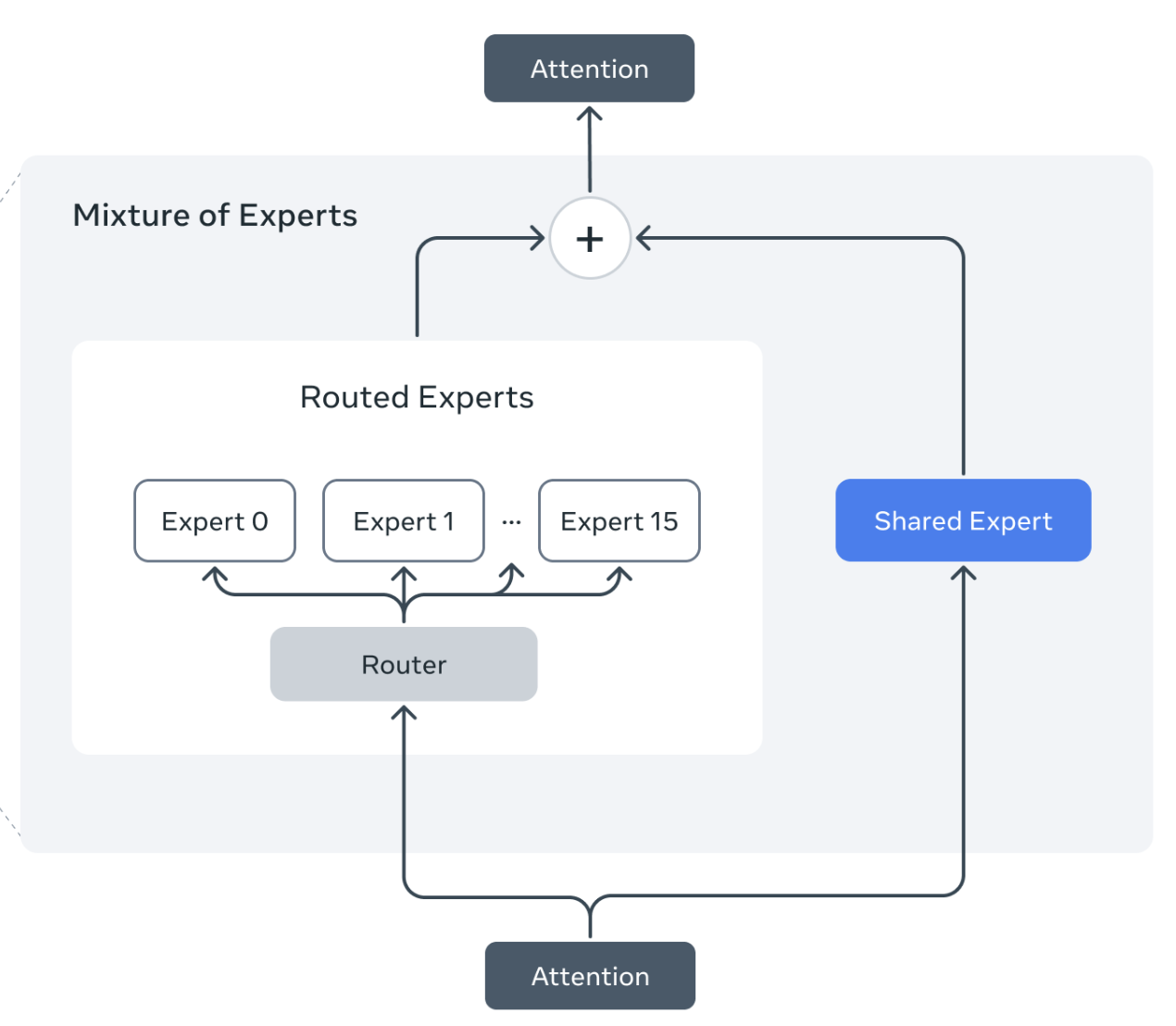
Llama research team.
2025
Llama 4 MoEs present a unique set of challenges for RL training, demanding both algorithmic and infra improvements.
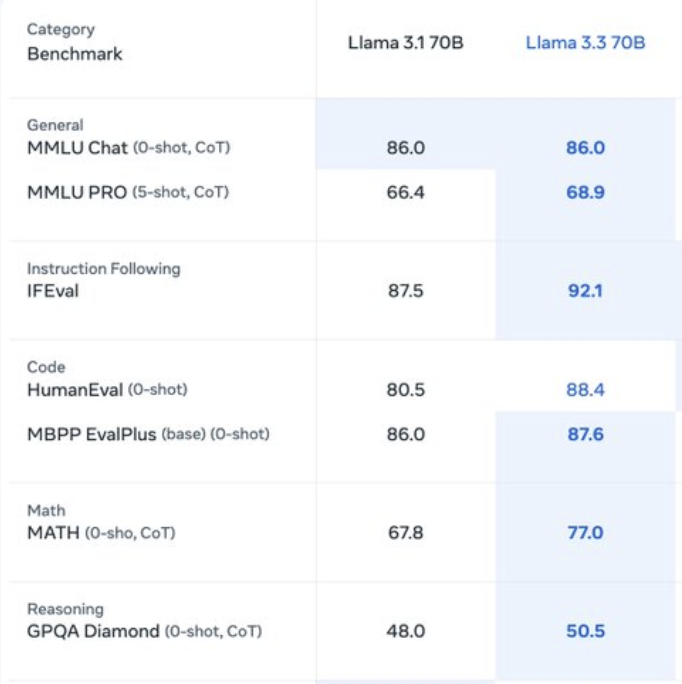
Llama research team.
2024
Llama 3.3 is the first Llama model trained with a large-scale RL stack, reasonable in model size while approaching the performance of Llama 3.1 405B in certain domains.
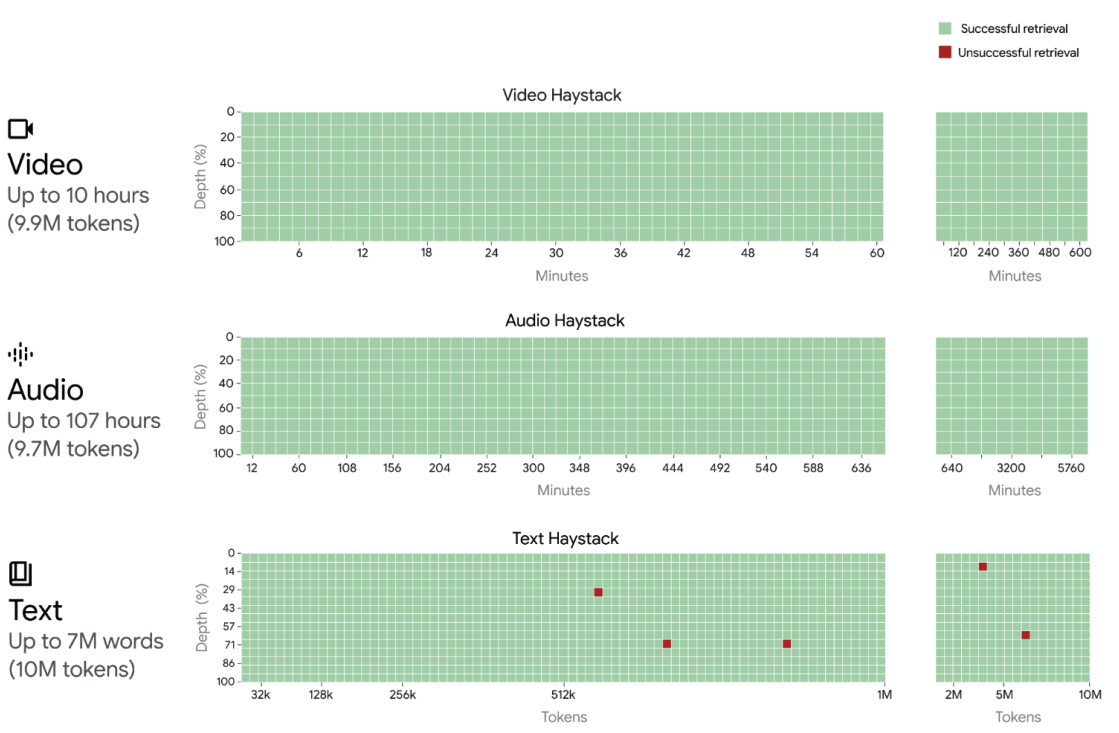
Gemini team, Google DeepMind.
2024 · Arxiv
Long context allows for exciting use cases such as tool use and agentic workflows to complete more complex tasks.

Gemini: A Family of Highly Capable Multimodal Models
Gemini team, Google DeepMind.
2023 · Tech report / Arxiv
One of the most powerful multi-modal large language models thus far in the world.